After a lot of flailing, I’ve finally found a method of learning from ChatGPT (or other LLMs) that’s helpful for complex subjects.
In the past few years, I’ve gotten a lot of use from LLMs for small bounded problems. It’s been great if I have a compiler error, or need to know some factoid about sharks, or just want to check an email for social niceties before I send it.
Where I’ve struggled is in using it to learn something complicated. Not just a piece of syntax or a fact, but a whole discipline. For a while, my test of a new LLM was to try to learn about beta-voltaic batteries from it. This was interesting, and I did learn a bit. The problem was that I felt adrift and didn’t know how to go past a few responses to dig into what really mattered in the physics of the topic. It worked as a test of the LLM, but not for learning the topic.
Today I tried having ChatGPT teach me about SLAM, and it worked surprisingly well. The main difference was that I went in with an outline of what I wanted to learn. Specifically, I used this list of 100 interview questions. This gave me a sense of progress – I knew I was learning something relevant to my topic. It also gave me a sense of what done looked like – it was very obvious that I still had 46 questions to go, so I hadn’t explored everything yet.
My overall method was:
go question by question
Try to answer on my own
pose the question to ChatGPT
explore ChatGPT’s answer until I understood it fully
Add new info to anki so I’d remember it later
What makes this work? The external sense of progress and done-ness certainly helped. Another aspect of this is that it was like an externally guided Feynman technique. I was constantly asking myself questions and trying to answer them. Then I compared my answer to an immediate nigh-expert-level answer.
This is better than books or papers (at least where the topic is already in the LLM), because I get an immediate answer without having to search through tens of pages. It’s maybe not better than talking to a real practicing expert, because a human expert might be better at prompting me with other questions or pointing out thorny issues that the LLM misses.
In fact, this whole process has made me realize how similar the Feynman technique is to a Socratic dialog. Probably the Socratic dialog is ideal, and the Feynman technique is what you fall back on when you don’t have access to a Socrates. My list of interview questions acted like a Socrates, priming the question pump for a ChatGPT fueled Feynman technique.
The obvious next question is how do I do this for a less structured topic? What if I don’t have a list of 100 questions to answer for a well studied and documented topic?
I have two ideas for this:
Come up with a project (a program, an essay) that demonstrates that I know something. Then ask myself and the LLM questions until I’m able to complete the project.
Get more comfortable having a conversational back and forth with an LLM. Asking it questions and prompting it to be more Socratic with me.
This reminds me a lot of my priorlearning experiments. They had definite goals: write a blog post explaining some topic. Doing this required me to actually go deep and understand things, which my beta-voltaic explanation test for LLMs really didn’t. These ideas also force more question decomposition, which was one of the major benefits of my prior experiments too.
In fact, maybe the main takeaway here is that learning from an LLM can be done just by slotting the LLM into the “reading” step of the Knowledge Bootstrapping method.
The company I work for has a lot of drivers, and they want those drivers to be safe. To help with that, all drivers have to take a Control Clinic class where they learn to respond to emergency situations in a vehicle. Turns out anyone at my company can take this class, so I took advantage of this and took the course last week.
In spite of working for a car company these days, I’m not really a car person. I work for a car company so that people in general can pay less attention to their cars. My thought is that most drivers already don’t pay enough attention, so we might as well make the cars safe for that.
The Control Clinic was at a race track, taught by car-guys, and gave me a bit of a window into their world. It was awesome, and I understand now why people get into racing. The drop in your stomach as you accelerate down a hill, racing your prior time, is exhilarating. In the control clinic, I only felt this as a passenger, but it has me planning to race again soon.
It wasn’t just fun though. I learned a lot from the clinic.
Geometry and Control
Cars have a lot more agility than I realized. I ended up doing a lot of different exercises, all of which pushed my ability to drive the car with enough control. In each case, the limitation was me and not the vehicle. When I was able to see and react, the car did exactly what I asked of it. One exercise had us braking and swerving to avoid a kid-simulating cone. At 70mph, I was able to do this even when starting my swerve only 20ft from the cone.
The main limitation on controlling a vehicle is often the driver. This is especially true on public roads where drivers are often not well trained and not focused.
On a racing track, I was surprised by just how much of racing is the driver being able to predict the curves of the track. A lot of racing, at least at the low level I’m at, is just a geometry problem. How do you create the smoothest curve around the whole track?
For our training, they put out cones on the edges of the road. You look from cone to cone, as soon as you’re at one your eyes are looking at the next, or maybe the cone two or three down. The cones help you identify the optimal curve around the track as you drive it. Once you know where the car needs to go, the rest of racing is a control problem. How do you keep your car as close to that curve as you can?
The emphasis in the control clinic was the positive goal: you steer where you look. This is exactly what they told me 20 years ago in driver’s ed, back when they showed pictures of cars that crashed into the only tree in a field. The driver was looking at the thing they were scared of, and their hands pulled the wheel to match their gaze.
As I learned with the cones at the edge of the track, it’s best to look far away. You want to be looking to the next waypoint you want to hit instead of where your car is immediately going. This lets you visualize where the optimal curve of the track is. Following this optimal curve, two “turns” in the track could be a single long and shallow pull on the steering wheel.
The control part of racing is the part that encompasses the vehicle. What I was really surprised by was the Control Clinic’s emphasis on traction budgets. As they put it, you only have so much traction available to the vehicle. If you’re allocating all of that traction to steering, you have none left over for braking. If you have all of your traction allocated to braking, your vehicle will under steer.
This, by the way, is the purpose of anti-lock brakes. ABS systems aren’t primarily intended to help you stop sooner. They give you steering control while you’re stopping. You have to use that steering control to be sure that you don’t hit anything as you slow down. Highly skilled racers will threshold brake, where they brake just to the point that ABS would kick in, then hold it under the threshold. This minimizes stopping distance while maintaining steering.
The idea of a traction budget reminds me a lot of the concept of control authority in aviation. Control authority is a measure of how much impact control inputs (like steering, braking, or accelerating) have on the actual vehicle motion. When a car goes into a skid, you lose traction and thus control authority.
Observability
One surprising thing about driving fast is that you can get a really good sense for what a car “wants” to do. Where is the steering wheel pulling when you lose traction in your back wheels? What’s the feel of the brake pedal as you approach ABS? Where is the momentum of the car pointed during the turn?
The more you learn to understand what the car is telling you, the more you can control how the vehicle moves through space.
One training tool the clinic used was a car with what were essentially training wheels on each back wheel. Those training wheels barely touched the ground, but they reduced traction enough that you could make the car spin out very easily. This simulates driving on ice or snow. The first time you feel the car skidding out, it feels like there’s no possible way to maintain control. After experiencing it a few times, I learned how to listen to the vehicle. While fishtailing, you can feel where the car wants to go, or where it has steering authority. If you control when you hit the accelerator just right, you can drive out of surprisingly serious skids.
One of the keys to this was that I kept my eyes locked where I wanted to go. That, along with my sense for how the vehicle was moving, was enough to let me guide the car even when there was no traction in the rear wheels.
In some ways, driving under these circumstances is a good metaphor for life. Driving like this requires you to know what the vehicle is doing now, where you want to go, and have the ability to control the vehicle in between. This reminds me a lot of the Likke model of strategy: means, ends, and ways.
The human element
The instructor I had riding shotgun for the class was very snarky. He joked a lot about me and the other students, guessing at our skills. He wasn’t particularly mean about it, but he also wasn’t nice. At first I thought this was just his personality. The more the class went though, the more I realized he was trying to get us to take it less seriously. His snark about what we were doing focused us on the task, but it also made us laugh.
Being able to smile was surprisingly helpful. I noticed that I performed a lot better when I was relaxed but focused. I didn’t want to be taking it easy, but I did want to avoid psyching myself out.
In a similar vein, driving with other people near you on the track is very distracting. This is basically the same on the track as it is on a daily commute. Driving can be pretty fun when nobody else is around. As soon as others are driving near me, the inherent unpredictability adds a lot of stress.
In the course, we did a stopping exercise with two cars. An instructor drove one car, while I drove another immediately behind him. I was one lane over, but trying to maintain 1 to 2 car lengths between the cars. The goal of the exercise was that when the instructor in front slammed on his brakes, I could stop my car before going past his. In a highway scenario, failure would amount to rear ending a vehicle if it has to stop suddenly.
The instructors did a great job trying to be distracting, and successfully got me to glance at my speedometer during this exercise. That half-second switch of my eyes caused me to be late on braking, blowing past the forward car. What I realized doing this is that can only really pay attention to one and a half things on the road.
I drive on public roads because other people are highly predictable. I don’t actually need to pay attention to them much at all. But sometimes that’s not true, and having been paying attention to the right things can save your life.
In the long term, one of the reasons I’m hopeful about autonomous vehicles is that they are always paying attention. In the short term, I’m glad I have a few more tools in my driving tool belt after taking this class.
I fall more into Zvi’s camp that Achaim’s, but I also think some of Achaim’s suggestions are much more generalizable than either of them realize.
In particular, if we knew how to create an AI that didn’t have any risk of massive economic wipeouts, as Achiam suggests, we’d be able to use that for something much more important than protecting our financial nest-egg. Specifically, we could make an AI that would be able to avoid massive wipeout risks to humanity.
Corrigibility and Humanity Wipe-Out Risk
Let’s assume some super-intelligent AI is an agent attempting to get value according to its utility function. In optimizing for that utility function, it may take actions that are bad for us humans and our utility function. Maybe they’re really bad, and the AI itself poses a wipeout risk to humanity.
To avoid having your AI wipe out humanity, you might want to install an off switch. If you notice it attempting to destroy humanity, you press the off switch. Easy-peasy, problem solved.
But wait! What if the AI doesn’t want you to press the off switch? It may destroy the off switch, ignore it, prevent you from pressing it, or do any number of other bad things. Just having an off switch doesn’t actually solve much.
Enter moral uncertainty. This idea, often explored by Stuart Russell’s research group, is that you don’t give the AI a utility function. Instead you make it learn your own utility function in some way. Often this involves giving the AI some collection of utility functions, each of which it has some probability of being true. The AI is uncertain what the real utility function is that it’s supposed to be optimizing for. It also understands that humanity is the best information source about what utility really is.
For a morally uncertain AI, the off-switch becomes just a signal to be listened to. One signal among many that indicates what humans think and feel and value. Of course the AI would listen to it, so that it can better learn about and then optimize true utility.
Oh, wait. Oops. That also has problems. As Eliezer shows, a morally uncertain AI being asked to shut down may still refuse and keep doing actions we humans think are bad. In fact, Russell’s research group also showed this would happen under several assumptions.
Eliezer’s argument is called “the problem of fully updated deference“, and is specifically about future available value. As far as I can tell, this problem wraps up three separate possible failures of moral uncertainty. Failure 1 is that the morally uncertain AI won’t even be able to converge on our true human value, a risk that Ivan Vendrov addresses over on LessWrong. Failure 2 is that the AI will choose to ignore an off-switch because it knows it will learn better later. Failure 3 is that in the far future, after the AI has learned everything it can from humans, it will then ignore them and just do whatever most maximizes it’s own “fully-updated” value.
Let’s explore more about Failure 2. The problem goes something like this:
The AI comes up with an action it thinks will optimize human values in the long term, even given that it’s uncertain about those values.
Humans look at the AI’s actions and say “Nuh-uh. This seems bad.” They tell the AI to shut down
The AI thinks very quickly to itself: if I shut down now, I get no more value at all. If I continue on and keep learning, then in the far future I’ll be able to get so much value that it overwhelms the immediate loss of ignoring the off switch.
The AI continues doing the bad thing.
In other words, the AI is willing to risk immediate losses in return for future enormous gains, even if we humans consider those future enormous gains to be vanishingly unlikely. This failure mode due to fully updated deference is similar to another, more well-known problem in decision theory: the St. Petersburg Paradox.
The St. Petersburg Paradox
The St. Petersburg Paradox starts with a coin-flipping game. On each round, you flip a coin. If the coin is heads, you get double your money from the last round and the game ends. If the coin is tails, you go on to the next round.
Here are a few ways the game can go:
H: $1
TH: $2
TTH: $4
TTTH: $8
and so on…
The paradox arises when I ask you to tell me how much you’d pay me to let you play this game. In theory, there’s a probability of astronomical winnings. In fact, there’s a non-zero probability of getting more than any finite number of dollars from this game. Want to be a trillionaire? All you need is to flip 39 tails in a row.
It’s been argued that a utility maximizing agent should be willing to pay literally all of its money to play this game once. The expected value from playing is \sum_n (\frac{1}{2})^n2^{n-1}.
This infinite sum diverges, meaning that the expected amount of money you win is infinite.
This doesn’t really accord with our intuitions though. I personally wouldn’t want to pay more than $5 or $10 to play, and that’s mostly just for the fun of playing it once.
Rationalists and twitter folks got an introduction to the St. Petersburg paradox last year when FTX founder Sam Bankman-Fried suggested he’d be willing to play the St. Petersburg paradox game over and over, even if he risked the destruction of the earth.
St. Petersburg and Corrigibility
Let’s compare the problem of fully updated deference to the St. Petersburg paradox. In both cases, an agent is faced with a question of whether to perform some action (ignore the stop button or play the game). In both cases, there’s an immediate cost to be paid to perform the actions. In both cases, there’s a low probability of very good outcome from the actions.
I claim that one small part of AI safety is being able to make agents that don’t play the St. Petersburg coin flipping game (or at least that play it wisely). This solves Achaim’s small object-level problem of financial wipeouts while also contributing to Zvi’s AI notkilleveryoneism goal.
One of the key points in the resolution of the St. Petersburg paradox is that we want to maximize wealth gain over time, rather than the expected wealth gain. This is a subtle distinction.
The expected value of wealth is what’s called an ensemble average. You take the probability of each possible outcome, multiply it by the value of the outcome, and sum. In many cases, this works just fine. When you face problems with extreme value outcomes or extreme probabilities, it results in issues like the St. Petersburg paradox.
One alternative to ensemble averages is the time average. In this case, we are not taking the time average of wealth, but of wealth-ratios. This is justifiable by the fact that utility is scale invariant. How much utility we start with is an accident of history. Whether we start with $10 or $10,000, a double of money doubles utility. In other words, we care about the rate of increase in utility from a bet more than we care about the absolute magnitude. This rate is what we actually want to maximize for the St. Petersburg paradox, as described in this excellent paper by Ole Peters.
The corrigibility issue we’re considering here comes up because the AI was described as maximizing expected value of utility, rather than maximizing expected ratio of increase in utility.
Note that some disagree about maximizing wealth ratio increases, as described by Abram Demski on LessWrong. I think maximizing ratio of increase makes way more sense than expected value, but that needs more justification than I give here.
Avoiding the St. Petersburg Paradox Using the Kelly Criterion
Before we can say how an AI should remain corrigible, let’s consider why it’s a bad idea to pay a lot in order to play the St. Petersburg coin flipping game.
One of the better explanations of this comes in response to the FTX implosion, explaining why Sam Bankman-Fried’s risk model was wrong. Taylor Pearson covers it in depth on his blog, but I’ll summarize here.
Ergodicity is the key point behind our (correct) intuition that we shouldn’t mortgage our house to play this game. Probabilistic systems are ergodic if a long-run observation of their output is the same as a bunch of short repeated trials. Technically, it means that the ensemble statistics match the temporal statistics. In other words, it’s ergodic if there isn’t really a “history” to the process. Coin flips are ergodic, because it doesn’t matter if you flip one coin 100 times or 100 coins 1 time, the number of heads has the same probability.
However, runs of coin flips are not ergodic if you have a stopping condition. Flipping 100 coins is not the same as flipping 1 coin until you get a heads. Taylor Pearson gives the example of Russian Roulette as a non-ergodic game: six people playing it once is very different from one person playing it six times in a row.
Humans (other than SBF) don’t get paradoxed in St. Petersburg because they actually do care about what happens after the game ends. They care about the non-ergodic reality they live in, and they plan for and prepare for it.
Let’s think now about our AI. It currently faces a question: a human has pressed the shutdown button, what should the AI do? A key point here is that the AI is reasoning about its future learnings and actions. It is actively assuming that it has a future, and that it will learn more later. It seems reasonable to assume that the AI will face similar questions to this in the future as well (for example, maybe the human’s boss comes in and presses the button too).
We also want the AI to perform well in our specific universe. We don’t care if some miniscule fraction of possible worlds have glorious utopia if most possible worlds are barren.
These are two important assumptions: that the AI will face similar questions repeatedly and that we care about our own specific timeline more than multiverse ensemble averages. With these assumptions, we can use the non-ergodic St. Petersburg Paradox resolution to help make our AI corrigible. (I’ll wait while you go read that paper. It has a much better explanation than I could write about non-ergodicity).
This brings us around to the Kelly Criterion, which as Pearson puts it is “the practical implementation of […] ergodic theory”. The Kelly Criterion is about optimizing your time average wealth in this universe, not your ensemble average wealth over many universes. When you face any question about how much you should pay to get a chance at winning a huge value, the Kelly criterion can give you the answer. It let’s you compare the cost of your bet to the expected time-average of your financial gain (ratio).
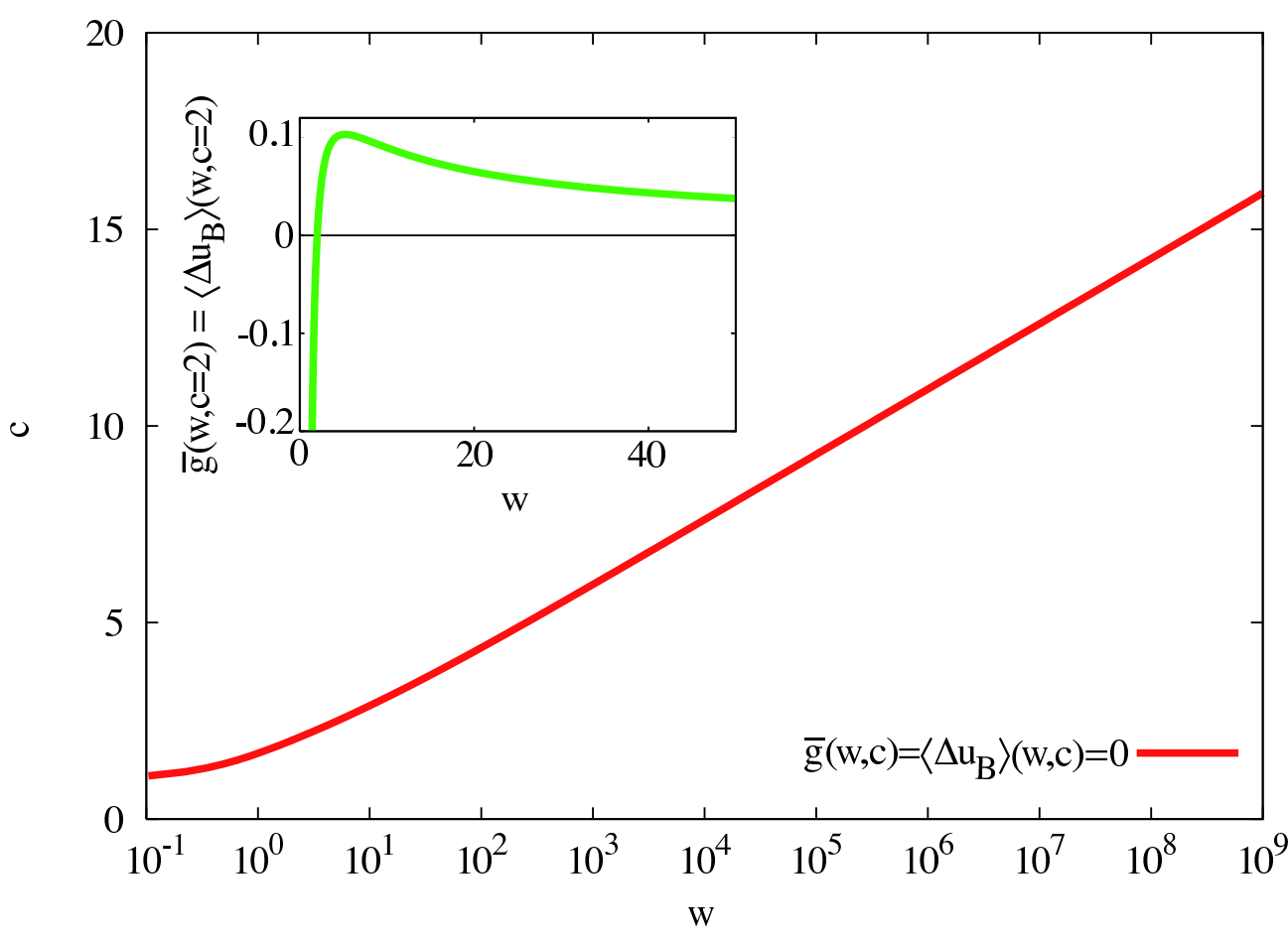
What does the Kelly criterion say about the St. Petersburg paradox? Let’s actually look at the solution via time averaging from Ole Peters, instead of using the Kelly Criterion directly. In this case, we’re trying to maximize: \sum_n (\frac{1}{2})^n [\ln(w-c+2^{n+1})-\ln(w)].
Here:
n is the number of tails flips we get
w is our starting wealth
c is the buy-in cost to play the game
This is a converging function. If we vary c to see when this function goes positive, it tells us the max we should be willing to bet here. It’s a function of your current wealth, because we’re maximizing our geometric growth rate. Since the actual St. Petersburg problem doesn’t return a formal “odds” value, we have to calculate it ourselves based on how much money we start with.
Don’t pay more than the red line on this plot if you want to come out ahead on the St. Petersburg coin-flipping game.
To bring this back to the AI safety realm, using a Kelly criterion to decide on actions means the AI is trying to balance risk and reward now, rather than betting everything on small probabilities of huge benefit.
I’ve focused on the Kelly criterion here, because it offers an explicit answer to the St. Petersburg paradox and the off-switch game. In general, AI agents are faced with many more varied situations than simple betting games like this. When there’s more than one action possible, or more than one game to choose from, the Kelly criterion gets very complicated. We can still use the geometric growth rate maximization rule, we just need to brute force it a bit more by computing mean growth rates directly.
Applying Geometric Growth Rate Maximization to AI Agents
We only need to worry about the Kelly criterion for AI agents. AIs that don’t make decisions (such as advisers, oracles, etc.) don’t need to be able to trade of risk in this way. Instead, the users of AI advisers would make those tradeoffs themselves.
This unfortunately doesn’t help us much, because the first thing a human does when given a generative AI is try to make it an agent. Let’s look at how AI agents often work.
The agent loop:
present problem to agent
agent chooses an action
agent executes the action
agent observes the reward from executing the action
agent observes a new problem (go to step 1)
In this case, the “reward” might be as concrete as a number of points (say from defeating a villain in a game) to something abstract like “is the goal accomplished yet?”
The key thing we want to worry about are how the agent chooses an action in step 2. One of the more common ways to do this is via Expected Utility maximization. In pseudo-code, it looks like this:
def eum_action_selection(problem, possible_actions):
selected_action = possible_actions[0]
value = -infty
for action in possible_actions:
# Computes the mean of ensemble outcomes
new_value = 0
for possible_outcome given problem and action:
new_value += outcome_reward * outcome_probability
if new_value > value:
value = value
selected_action = action
return selected_action
The way this works is that the AI checks literally all its possible actions. The one that it predicts will get the most reward is the one it does.
In contrast, a non-ergodic selection algorithm might look something like this:
def kelly_action_selection(problem, possible_actions):
selected_action = possible_actions[0]
value = -infty
w = starting reward given problem
for action in possible_actions:
# Compute temporal average over outcomes
new_value = 0
c = cost to take action given problem
for outcome given problem and action:
ratio = log(w-c+outcome_reward) - log(w)
new_value += ratio * outcome_probability
if new_value > value:
value = value
selected_action = action
return selected_action
An important point to note about this algorithm is that in many cases is provides the same answer as expectation maximization. If faced with only costless actions, both algorithms give the same answer.
Immediate Takeaways
This post has been very abstract so far. We’ve talked about ensemble averages, time averages, and optimization criteria for agents. What we haven’t talked about is GPT, or any of the GPT-enabled agents that people are making. What does all this mathematical theory mean for the people making AI agents today?
In general, the GPT-based agents I have seen prompt the AI to generate next actions. They may go through a few iterations to refine the action, but they ultimately accept that AI’s judgement as-is. The GPT response (especially at low temperature values), is the most probable text string from ChatGPT. If you have a prompt telling GPT to effectively plan to reach goals, that’s going to cache out by generating actions that might be written down by a human. It’s anyone’s guess at this point how that is (internally and invisibly) evaluated for risk and reward.
What we need is to make GPT-based agents explicitly aware of the costs of their actions and their likelihood of success. This allows us to make wiser decisions (even wiser automated decisions).
There are people already doing this. Google’s SayCan, for example, explicitly calculates both the value and chance of success for actions proposed by an LLM. It currently relies on a pre-computed list of available actions, rather than allowing the LLM to propose any possible action. It also depends on an enormous amount of robotics training data to determine the chance of action success.
For those making general purpose AI agents, I ask you to stop. If you’re not going to stop, I ask you to at least make them risk aware.
The problem isn’t solved yet
Even if you could generate all of the reward values and probabilities accurately, this new decision metric doesn’t solve corrigibility. There are still cases where the cost the AI pays to disobey a shutdown command could be worth it (according to the AI). We also have to consider Fully Updated Deference Failure 3, where the AI has learned literally everything it can from humans and the off-switch provides no new data about value.
There are some who bite this bullet, and say that an AI that correctly sees enormous gain in utility should disobey an ignorant human asking it to turn off. They assume that this will let aligned powerful AIs give us all the things we don’t understand how to get.
I don’t agree with this perspective. If you could prove to me that the AI was aligned and that it’s predictions were accurate, then I’d agree to go forward with its plans. If you can’t prove that to me, then I’d suspect coding errors or mis-alignment. I wouldn’t want that AI to continue, even if it thought it knew better.
The idea of corrigibility is a bit of a stop-gap. It let’s us stop an AI that we may not trust, even if that AI might be doing the right thing. There are so many failure modes possible for a superintelligent AI that we need safety valves like corrigibility. Perhaps every time we use them, it turns out they weren’t necessary. It’s still good to have them.
Think about a rocket launch. Rocket launches are regularly rescheduled due to weather and hardware anomalies. Could the rocket have successfully launched anyway? Possibly! Could we have been mistaken about the situation, and the rocket was fine? Possibly! We choose not to take the risk in these situations. We need similar abort mechanisms for AIs.
A slow and expensive way to solve the Deep Fakes problem with camera root-of-trust
I wrote this a few years ago and shopped it around to a few orgs. No one was interested then, but deep fakes continue to be a big issue. I’m posting here in case it inspires anyone.
Recent improvements in Deep Learning models have brought the creation of undetectable video manipulation within reach of low resource groups and individuals. Several videos have been released showing historical figures giving speeches that they never made, and detecting that these videos are fabricated is very difficult for a human to do. These Deep Fake videos and images could have a negative impact on democracy and the economy by degrading public trust in reporting and making it more difficult to verify recorded events. Moreover, Deep Fake videos could negatively impact law enforcement, defense, and intelligence operations if adversarial actors feed incorrect data to these organizations.
These problems will only increase as Deep Learning models improve, and it is imperative that a solution be found that enables trusted video recording. One naïve way of detecting Deep Fakes would be to fight fire with fire, and create Deep Learning models that can detect manipulated video and images. This mitigation method is likely to lead to a Red Queen race in which new defensive models are constantly being superseded by new offensive models. To avoid this, I recommend the adoption of hardware root-of-trust for modern cameras. Combined with a camera ID database and automated validation software plug-ins, hardware root-of-trust would allow video producers to provably authenticate their footage, and video consumers to detect alterations in videos that they watch.
The proposed hardware system will allow for the production of provably authentic video, but it will not allow old video to be authenticated. It provides a positive signal of authenticity, but videos and images that do not use this system remain suspect.
In order to minimize the risk of Deep Fakes, a system similar to the one proposed here must be driven to near ubiquity. The ubiquity of this system will cause videos that are not produced with this system to be viewed with suspicion, increasing the difficulty of fooling viewers with Deep Fakes. If, on the other hand, many videos are produced without using such a system, then the lack of this system’s positive signal will not inspire enough distrust in viewers and Deep Fakes may still proliferate.
Hardware Root-of-Trust for Video
In order to trust an image or video, a viewer needs to be sure that:
The video was created by a real camera
The video was not tampered with between creation and viewing
These two goals can be accomplished by the use of public key cryptography, fast hashing algorithms, and cryptographic signing.
I propose the integration of a cryptographic coprocessor on the same silicon die as a camera sensor. Every frame produced by the sensor would then include metadata that validates that frame as being provably from that specific camera. Any changes to the pixels or metadata will lead to a detectable change in the frame.
Secure Frame Generation
When the camera sensor is being manufactured, the manufacturer will cause a public/private key pair to be generated for that sensor. The sensor itself will generate the keys, and will contain the private key on an un-readable block of memory. Only the public key will ever be available off-chip. The sensor will also have a hardware defined (set in silicon) universally unique identifier. The sensor manufacturer will then store the camera’s public key and sensor ID in a database accessible to its customers.
No changes need to be made in the hardware design or assembly process for imaging hardware. Secure sensors can be included in any device that already uses such sensors, like smartphones, tablets, and laptops.
The consumer experience of creating an image or video is also unchanged. Users will be able to take photos and video using any standard app or program. All of the secure operations will happen invisibly to the user.
Whenever a secure image is taken using the sensor, the sensor will output the image data itself along with a small metadata payload. The metadata will be composed of the following:
The ID of the camera
The plaintext hash of the prior secure frame grabbed by this camera sensor
A cryptographically signed package of:
The hash of the current secure image frame
The hash of the prior secure image frame
The inclusion of the hash of the prior frame allows users to ensure that no frames were inserted between any two frames in a video. When the image or video is displayed in a normal viewer, the metadata will not be observable.
Secure Frame Validation
Any user who wishes to validate the video or image will need to run the following procedure (which can be automated and run in the background using e.g. a browser plug-in):
Read the metadata of the first frame
Look up the public key of the image sensor by using its ID (from the metadata) with the sensor manufacturer’s database
Hash the first frame
Compare the hash of the first frame to the signed hash included within the frame’s metadata (requires public key of the sensor)
In a video, subsequent frames can be validated in the same way. Frame continuity can be validated by comparing the signed prior-hash in a frame’s metadata with the calculated hash of the prior frame in the video.
Viewers can be certain that the image or video is authentic if the following criteria are met:
The sensor ID is the same in all frames
The signed image hash matches the calculated image hash for all frames
The signed hash was created using the private key that corresponds to the public key retrieved using the sensor’s ID
Each frame’s signed prior hash matches the hash from the prior frame in the video (not necessary for single images or the first frame in a video)
If any of the above criteria fail, then the viewer will know that an image was tampered with.
Implementation Plan
Prototype Hardware
The system described above can be prototyped using an FPGA and off-the-shelf camera sensor. A development board can be created that connects the camera’s MIPI CSI interface directly to the FPGA. The FPGA will be configured to implement the cryptographic hashing and signing algorithms. It will then transmit the image and metadata over a second MIPI CSI interface to the device processor. In effect, the prototype will have an FPGA acting as a man-in-the-middle to hash and sign all images.
The FPGA will be configured with a cryptographic coprocessor IP core. In addition to the hashing and signing algorithm, the core will also handle the following command and control functions:
Generate a new public/private key pair
Divulge public key
Lock device (prevent re-generation of public/private keys)
Invalidate (delete public/private key pair and lock device)
Query device ID
Set device ID (for FPGA prototype only; actual hardware will have ID defined at fabrication time)
The IP core on the FPGA would use an I2C communication interface, the same as the control interface for most CMOS camera sensors. Two options exist for communicating with the FPGA.
The FPGA is a second device on the I2C bus with its own address. The application processor would have to know about it and use it explicitly.
The FPGA acts as an I2C intermediary. The application processor would talk to the FPGA assuming that it was the camera IC, and any non-cryptographic commands would be forwarded to the camera itself. This method is more similar to the final hardware, in which the crypto engine is embedded on the same die as the camera sensor.
Validation Tools
The validation tools can be separated into the server-based camera lookup database and client-based video analysis software. The video analysis software can be written as a library or plug-in and released publicly, allowing the creation of codecs and apps for commonly used software.
During the prototyping and proof of concept, these libraries can be created and several test plug-ins written for video players. This will then serve as a useful base for the productization phase of the project.
Productization
While the FPGA-based prototype described above serves as a useful proof-of-concept, the end-product will need the cryptography engine to be located on the same die (or at least the same IC) as the camera sensor. This ensures that the images can’t be tampered with between the CMOS sensor itself and the cryptographic signing operation.
I propose that the cryptographic engine IP used on the FPGA be open-sourced and a consortium formed between camera sensor manufacturers (e.g. Omnivision) and integrators (e.g. Amazon). The consortium can be used to drive adoption of the system, as well as refining the standards.
Initially, cameras that include this security system may be more expensive than cameras that do not. We propose creating a higher tier product category for secure image sensors. These can be marketed at government, intelligence, and reporting organizations. As old product lines are retired and new ones come online, manufacturers can phase out image sensors that do not include this secure system.
Funding Progression
A small team implementing the initial prototype hardware could be funded by contracts from organization that stand to benefit the most from such hardware, such as DARPA. If the prototyping team were a small company, they could potentially find SBIRs that would suffice.
A large company, such as Amazon, may wish to invest in secure camera systems to improve their security camera offerings. Stakeholders in this plan would also benefit from the positive press that would result from fighting Deep Fakes.
After the initial proof-of-concept and IP development, the cryptographic engine must be integrated into image sensor ICs. The large investment required for this could come from secure camera manufacturers directly, or from potential customers for such a system.
After the first round of authenticable image sensors is available in the market, expansion will be fundable by reaching out to customers such as news organizations, human rights organizations, etc.
Open Questions
Data format conversion and compression is very common with video. How will a signed video be compressed and maintain authenticability?
Do there exist cryptographically compatible compression algorithms?
Can we create a cryptographically compatible compressed video format?
Risks
Attackers may attempt to hack the central database of camera IDs and public keys. If successful, this will allow them to present a fake video as credibly real. It would also allow them to cause real videos to fail validation.
Attackers may attempt to hack the validation plug-ins directly, perhaps inserting functionality that would lead to incorrect validation results for videos.
Provably authentic video could lead to more severe blackmail methods.
If this system does not achieve high penetration, then Deep Fakes could still proliferate that claim to be from insecure camera sensors. Only by achieving high market penetration will the return on investment of Deep Fakes fall.
A sufficiently dedicated attacker could create a Deep Fake video, acquire a secure camera, and then play the video into the camera using a high-definition screen. This would then create a signed Deep Fake video. To mitigate this issue, high security organization (e.g. defense or intelligence communities) are encouraged to keep blacklists and whitelists of specific camera sensors.
This risk can be mitigated in several ways. The most straightforward may be to include an accelerometer on the camera die as well. Accelerometer data could be signed and included in image frame metadata. Analysis could then be performed to correlate accelerometer data with video frames to ensure that their motion estimates agree.
Privacy and anonymity may be threatened if the public keys of an image can be identified as being from a specific camera/phone owned by a specific person. Ideally, the databased published by the camera manufacturers include only public keys and device serial numbers. The consumer device manufacturers would then be advised to randomize imagers among devices so it is harder to identify a photographer from their image. Additionally, zero-knowledge proof techniques should be investigated to improve privacy and anonymity while maintaining image-verification ability.
Imagine you’re a person. Imagine you have goals. You wander around in the world trying to achieve those goals, but that’s hard. Sometimes it’s hard because you’re not sure what to do, or what you try to do doesn’t work. But sometimes it’s hard because what you thought was your goal actually sucks.
Imagine you want to be happy, so you try heroin. It works alright for a bit, but you end up more and more miserable. Your health, happiness, and safety decline significantly. What happened here? It seemed so promising when you started.
This is the problem of corrupt reward channels. What seems good while you’re doing it is, from the outside, obviously very bad.
Now imagine you’re a person with goals, but you want to build a robot to achieve those goals. How do you design the robot to deal with corrupted reward channels?
Reinforcement Learning with a Corrupted Reward Channel
In 2017, a team from DeepMind and the Australian National University released a paper about how to handle the problem of corrupt reward channels in reinforcement learning robots. They came to the very sad conclusion that you can’t deal with this in general. There’s always some world your robot could start in that it would be unable to do well at.
Obviously things aren’t as dire as that, because humans do alright in the world we start in. The DeepMind team looked at how various tweaks and constraints to the problem could make it easier.
To start with, they formalize what they call a CRMDP (Corrupt Reward Markov Decision Process). This is a generalization of a normal Markov Decision Process where the reward that the robot sees is some corruption function of the real reward. The robot wants to maximize true reward, but only sees the output of this corruption function. The formalization itself just add the corruption function to the set of data about the MDP, and then specifies that the agent only sees the corrupted reward and not the real reward.
From this, they derive a “no free lunch” theorem. This basically says that you can’t do better in some possible worlds without doing worse in other worlds. If you already know what world you’re in, then there’s no corrupt reward problem because you know everything there is to know about the real world and real reward. Since you don’t know this, there’s ambiguity about what the world is. The world and the corruption function could just happen to coincidentally cancel out, or they could just happen to provide the worst possible inputs for any given reinforcement learning algorithm.
To do any better, they need to make some assumptions about what the world really looks like. They use those assumptions to find some better bounds on how well or poorly a RL agent can do. The bounds they look at are focused around how many MDP states might be corrupted. If you know that some percentage of states are non-corrupt (but don’t know which ones), then you can design an algorithm that does ok in expectation by randomizing.
Here’s how it works: the agent separates exploration and exploitation into completely distinct phases. It attempts to explore the entire world to learn as much as it can about observed rewards. At the end of this, it has some number of states that it thinks are high reward. Some of those might be corrupted, so instead of just going to the highest reward state, it randomly selects a state from among the top few.
Because there’s a constraint on how many states are corrupt, it’s unlikely that all the top states are bad. By selecting at random, the agent is improving the chances that the reward it gets is really high, rather than corrupted.
Humans sometimes seem to do reward randomization too. The paper talks about exploring until you know the (possibly-corrupted) rewards, then randomly choosing a high reward state to focus on. Many humans seem to do something like this, and we end up with people focusing on all sorts of different success metrics when they reach adulthood. Some people focus on earning money, others on being famous, others on raising a family, or on hosting good game nights, or whatever.
Other humans do something a bit different. You’ll often see people that seem to choose a set of things they care about, and optimize for a mix of those things. Haidt talks about this a bit when he compares human morality to a tongue with six moral tastes.
Seeing Problems Coming
While randomizing what you optimize for may improve things a bit, it’s really not the best approach. The ideal thing to do is to know enough about the world to avoid obviously bad states. You can’t do this in a standard MDP, because each state is “self-observing”. In a normal MDP, you only know the reward from a state by actually going there and seeing what you get.
The real world is much more informative than this. People can learn about rewards without ever visiting a state. Think about warnings to not do drugs, or exhortations to work hard in school and get a good job. This is information provided in one state about the reward of another state.
The DeepMind team behind the CRMDP paper calls this “decoupled reinforcement learning”. They formalize it by creating an MDP in which each state may give information about the reward of other states. Some states may not give any info, some may give info about only themselves, or only another one, or both. The way they formalize this in their new MDP, they assume that each state has a set of observations that can be made from it. Each time the agent visits that state, it randomly samples one of those observations.
A few years ago, I was thinking a lot about how an AI agent could see problems coming. Similar to the CRMDP paper, I thought that an agent that could predict low reward in a state it hasn’t been to yet would be able to avoid that state. My approach there was mainly to modify the agent-dynamics of an expectation maximizer. I wasn’t focused on how the agent learns in the first place.
I was doing engineering changes to a formal model of an agent. In this paper, they create a general specification of a way that agents can learn in the world. This is a lot more flexible, as it supports both model-free and model-based RL. It also doesn’t require any other assumptions about the agent.
It turns out that a lot of people have been thinking about this idea of seeing problems coming, but they’ve generally framed it in different ways. The CRMDP paper calls out three specific ways of doing this.
CIRL
Cooperative Inverse Reinforcement Learning (CIRL), proposed by a team out of UC Berkeley back in 2016, allows an agent to learn from a human. The human know they’re being observed, and so engages in teaching behaviors for the agent. Because the human can engage in teaching behaviors, the agent can efficiently learn a model of reward.
An important note here is that this is a variant of inverse reinforcement learning. That means the agent doesn’t actually have access to reward (whether corrupted or real). Instead the agent needs to create a model of the reward by observing the human. Because the human can engage in teaching behaviors, the human can help the agent build a model of reward.
The corrupt reward paper uses this as an example of observing states that you’re not actually in, but I’m not sure how that works in the original formalism. The human knows true reward, but the formalization of CIRL still involves only seeing the reward for states that you’re in. The agent can rely on the human to help route around low rewards or corruption, but not to learn about non-visited states.
Stories
Another approach uses stories to teach agents about reward in the world. This approach, which the CRMDP paper calls Learning Values From Stories (or LVFS), is as simple as it sounds. Let the agent read stories about how people act, then learn about the world’s real reward function from those stories. It seems that LLM’s like GPT could do something like this fairly easily, though I don’t know of anyone doing it already.
Let’s do a little digression on learning values from stories. The CRMDP paper gives the following example of corruption that may happen for a LVFS agent: an “LVFS agent may find a state where its story channel only conveys stories about the agent’s own greatness.”
As written, I don’t think this is right. If the agent finds a story that says literally “you’re great”. It doesn’t need to keep listening to that story. In the formalism of decoupled MDPs, \langle s', \hat{R}_s(s') \rangle is large \forall s' . That being the case, the agent can go do whatever it wants sure in its own greatness, so it might as well get even greater by maximizing other reward. In other words, this specific story seems like it would just add a constant offset to the agent’s reward for all states.
A natural fix to make the agent wirehead this story is “agent finds state where its story channel conveys the agent’s own greatness for listening to this story“.
This gestures at something that I think is relevant for decoupled CRMDPs in general: you can’t necessarily trust states that are self-aggrandizing. Going further, you may not want to trust cliques of states that are mutually aggrandizing if they aren’t aggrandized by external states. It would be pretty interesting to see further exploration of this idea.
Semi-Supervised RL
The last approach the CRMDP paper compares is Semi-Supervised Reinforcement Learning (SSRL) as described in a paper by Amodei et. al. In that paper (which also references this blog post), they define SSRL as “ordinary reinforcement learning except that the agent can only see its reward on a small fraction of the timesteps or episodes.” This is decidedly not a decoupled MDP.
Instead of being able to see the value of other states from the current state, you only get the value of the current state. And you only get the current state’s value sometimes. This is a sparse-reward problem, not a decoupled MDP.
The solution explored in SSRL is interesting, as it involves learning an estimated reward function to “upsample” the sparse rewards. The problem is that you’re still only seeing rewards for states that you’ve been (or perhaps states similar to ones you’ve been). Vastly different states would not have a reliable result from the learned reward predictor.
Decoupled Reward
The CRMDP paper claims that all of these methods are a special case of the decoupled RL problem. While the source descriptions of those methods often have explicit claims that imply non-decoupled MDP, their algorithms do naturally accommodate the decoupled MDP formalism.
In CIRL and SSRL, the reason for this is simply that they involve creating a reward-prediction model to supplement any reward observation. By adding the decoupled observations to that model, it can learn about states it hasn’t visited. Further modifications should be explored for those algorithms, because they don’t assume possible corruption of reward or observation channels.
The paper then goes on to make some claims about performance bounds for decoupled-CRMDP learners. Similar to the non-decoupled case above, they make simplifying assumptions about the world the agent is exploring to avoid adversarial cases.
Specifically, they assume that some states are non-corrupt. They also assume that there’s a limit on the number of states that are corrupted.
The non-corrupt state assumption is pretty strong. They assume there exists some states in the world for which real true rewards are observable by the agent. They also assume that these safe states are truly represented from any other state. Any state in the world will either say nothing about the safe states, or will accurately say what their value is.
Given these assumptions, they show that there exists a learning algorithm that learns the true rewards of the world in finite time. The general idea behind this proof is that you can institute a form of voting on the reward of all the states. Given that there’s a limit on the number of states, a high enough vote share will allow you to determine true rewards.
The implications the paper draws from this differ for RL, CIRL, LVFS, and SSRL. They find that RL, as expected, can’t handle corrupted rewards because it assumes the MDP is not decoupled. They then say that CIRL has a short time horizon for learning, but LVFS and SSRL both seem likely to do well.
I don’t follow their arguments for SSRL being worth considering. They say that SSRL would allow a supervisor to evaluate states s' while the agent is in a safe lab state s. I agree this would help solve the problem. This doesn’t seem all all like what SSRL is described as in the referenced paper or the blog post. Those sources just describe an estimation problem to solve sparse rewards, not to deal with decoupled MDPs. If the authors of the CRMDP paper are making the generous assumption that the SSRL algorithm allows for supervisor evaluations in this way, I don’t understand why they wouldn’t make a similar assumption for CIRL.
For me, only LVFS came away looking good for decoupled-CRMDPs without any modification. Formally, a story is just a history of state/action/reward tuples. Viewing those and learning from them seems like the most obvious and general way to deal with a decoupled MDP. The assumption that an SSRL advisor can provide \hat{R}(s') from a safe s is equivalent to LVFS where the stories are constrained to be singleton histories.
This seems intuitive to me. If you want to avoid a problem, you have to see it coming. To see it coming, you have to get information about it before you encounter it. In an MDP, that information needs to include state/reward information, so that one can learn what states to avoid. It also needs to include state/action/outcome information, so that one can learn how to avoid given states.
All of the nuance comes in when you consider how an algorithm incorporates the information, how it structures the voting to discover untrustworthy states, and how it trades off between exploring and exploiting.
Going Further
The paper lists a few areas that they want to address in the future. These mostly involve finding more efficient ways to solve decoupled-CRMDPs, expanding to partially observed or unobserved states, and time-varying corruption functions. Basically they ask how to make their formalism more realistic.
The one thing they didn’t mention is ergodicity. They assume (implicitly in that their MDPs are communicating) that their MDPs are ergodic. This is a very common assumption in RL, because it makes things more tractable. Unfortunately, it’s not at all realistic. In the real world, if your agent gets run over by a car then it can’t just start again from the beginning. If it destroys the world, you can’t just give it -5 points and try again.
Decoupled MDPs seem like the perfect tool to start solving non-ergodic learning problems. How do you explore in a way to avoid disaster, given that you could get information about disaster from safe states? What assumptions are needed to prove that a disaster is avoidable?
These are the questions that I want to see addressed in future work.
Robotics Transformers 1 (image courtesy of Google)
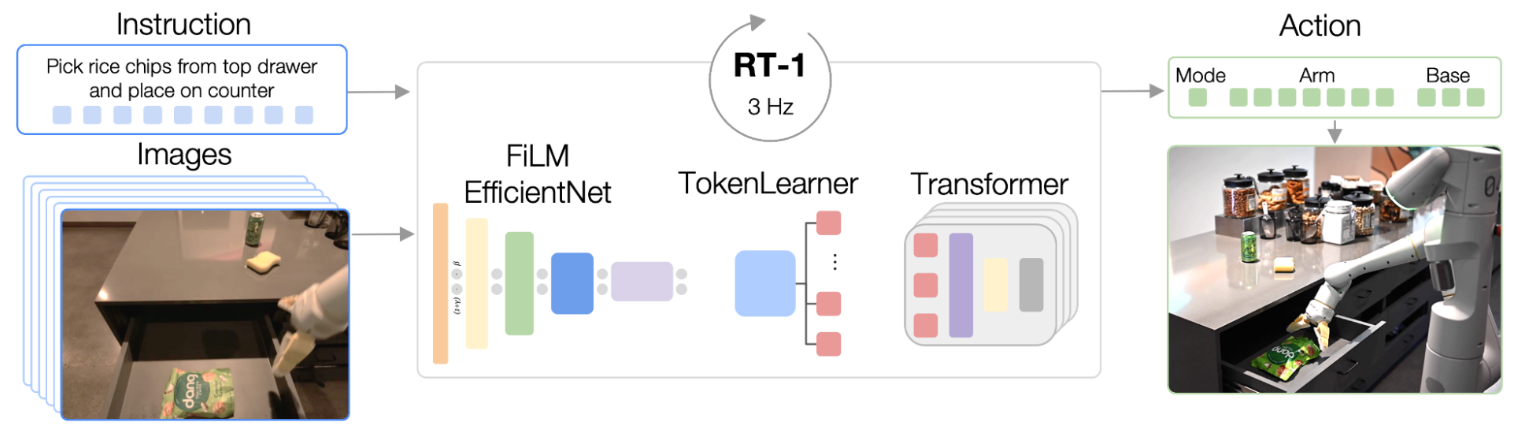
With ChatGPT taking the world by storm, it’s obvious to everyone that transformers are a useful AI tool in the world of bits. How useful can they be in the world of atoms? In particular, can they be used for robotics control. That’s the question answered by Google’s new paper on the Robotics Transformer 1 (RT1).
GPT and other large language models use collections of text, generally scraped from the internet, to learn how to do text completion. It turns out that once you know how to write the endings of sentences, paragraphs, and articles, then you can use that skill to answer questions. In fact, you can “complete the text” in a question/answer format so well that you can do pretty well on the SATs. If you can use transformers to get into college, can you also use them to walk (or roll) from classroom to classroom?
RT1 Overview
RT1 differs from GPT in that its input is camera images and text instructions (instead of just text). Its output is joint-angles (instead of more text). While GPT could be trained on text that people wrote for its own sake and put on the internet, RT1 was trained on recordings of robot tasks created for the sake of training it.
The goal is to create a network that can perform simple actions like “pick up the bottle” or “go to the sink”. These actions can then be chained (using something built on top of RT1) to create very complex behaviors.
The inputs to RT1 are a short history of 6 camera images leading up the current moment and the task description (in english). These camera images are sent to a pre-trained image recognition model. They just used EfficientNet, which they’d built a few years ago. Instead of taking the image classifications from their image recognition model, they take the output of a spatial feature map. I think this is the equivalent of chopping off the output portions of the image classification network and observing an internal layer. This internal layer encodes useful information about what’s in the image.
The internal layer encoding from EfficientNet is 9x9x512 values. They take those values and encode them into 81 tokens. I think that this means they just treat each 512 value array as a token, and then feed that into FiLM (PDF warning) layers to pick out useful information from each token based on the text description.
FiLM is a method of modifying network weights based on outside information. The overall idea (afaict) is that you have a FiLM generator that looks at outside information (in this case the task description in English) and outputs some coefficients. Then you have a FiLM layer in your neural net that takes these coefficients and uses them to tweak each value. In a fully connected network, every node in one layer impacts every node in the next layer. In a FiLM layer, each node in the prior layer impacts only one node in the FiLM layer.
Since the input to FiLM is the pre-trained EfficientNet, the only thing that needs to be trained at this point is the FiLM generator itself. The FiLM generator gets trained to modify the tokens according to the text input.
Once tokens are modified according to the text, they’re compressed by TokenLearner, another off-the-shelf project from Google. TokenLearner takes the tokens output from FiLM and uses spatial attention to figure out what’s important in them. It then outputs only 8 tokens to be passed to the next layer of the network. It selects 8 tokens for each of the 6 input images.
After the tokens for each image have been created, the data is sent to the transformer layers. RT1 uses 8 self-attention layers. In GPT, the attention is “temporal” in the sense that you’re attending to how early characters impact the probability of later characters. In RT1, the attention is both spatial and temporal. RT1 uses self-attention to figure out how pixels in one location and time impact the probability of pixel values in other locations and times.
Outputs are arm and base movements. Arm movements are things like position in space (x, y, z), orientation in space (roll, pitch, yaw), and gripper opening. Base movements are position and orientation as well, but (x,y) and (yaw) only. Each element in the output can take only one of 256 values. The output also contains a “mode” variable. Modes can be either “base moving”, “arm moving”, or “episode complete”.
Each of those 256 values per output element is a single output node of the network. There are thus 256 output nodes per dimension (along with the three nodes for mode). The actual values for each of these output nodes are treated as a probability for what action to actually take.
Training
The training data problem in robotics is a big deal. GPT-3 was trained on about 500 billion tokens. Since RT1 had to be trained on custom training data, it’s dataset was only 130 thousand episodes. I didn’t see how many total token were used in training in the paper, but if each episode is 1 minute long that’s only 23 million frames of data.
To get the training data, Google had people remote-control various robots to perform certain tasks. Each task was recorded, and someone went through and annotated the task with what was being done. It seems like the goal was to get recordings of tasks that would be common in the home: taking things out of drawers, putting them back, opening jars, etc. Those 130 thousand episodes cover 700 different types of task.
The paper makes it clear that they expect generalization in competence between the tasks. This requires tasks to be similar enough to each other that generalizations can be made. The RT1 data included tasks such as “pick apple” or “pick coke can”, so the similarity between their tasks is pretty clear.
The paper also includes some experiments on simulated data. They add simulated data to the experimentally collected data and find that performance on the original “real data” tasks doesn’t decrease. At the same time, performance on sim-only tasks does increase. This is great news, and may be a partial solution to the sim2real learning problem.
The paper was a bit light on details about the training itself. I’m not clear on how much compute it took to train. Many components of the model come pre-trained, which likely sped things up considerably.
Performance
With GPT-3, performance is generally just “how reasonable does the output text sound?”. In robotics there’s a more concrete performance criterion. Did the robot actually do the thing you told it to do? That’s a yes/no question that’s easier to answer.
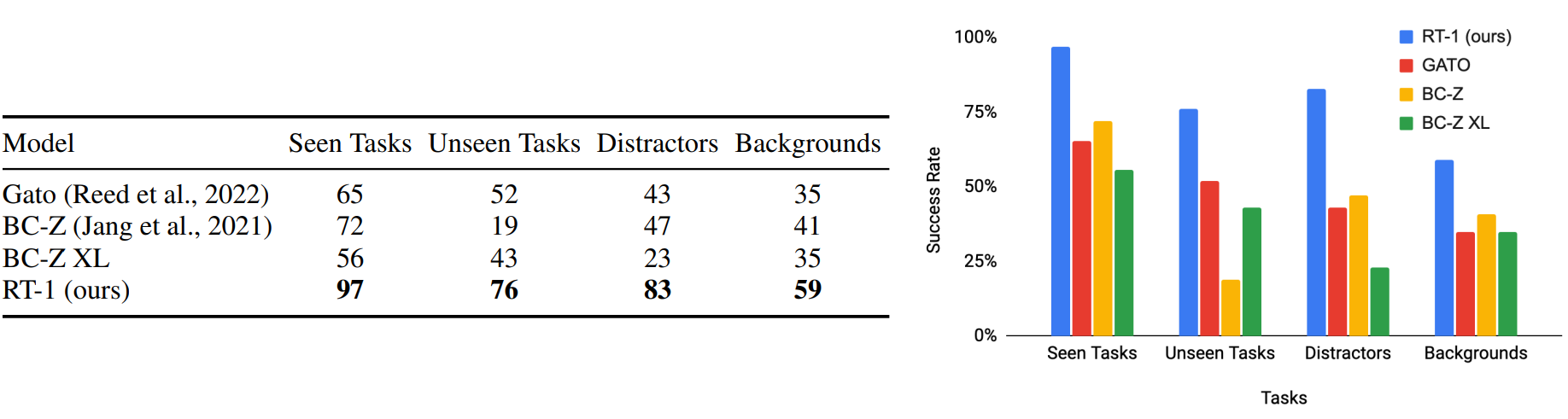
Google measured RT1’s performance on tasks it had seen in training, tasks similar to those seen in training but not identical, tasks in cluttered environments, and tasks that take long term planning. In each of these categories, RT1 outperformed the comparison models that Google was using.
Success rate of RT1 compared to state of the art. Plot and table from the paper.
It’s very cool to see a project that works well in cluttered environments (the “backgrounds” task). I have high hopes of having a robot butler one day. A lot of robotics algorithms work in the lab, but getting it to work in my messy home is another thing altogether.
The RT1 model is able to run at 3Hz, with 100ms being allocated to each inference step. The remaining 700ms is used by other tasks in the robot. This isn’t actually that fast as far as robots go, but it is fast enough to do a lot of household tasks. It couldn’t catch a ball, but it could throw away a food wrapper.
While the paper specifies inference time, it doesn’t specify the compute used for the inference (at least not that I could find). This seems like an odd omission, though it should be possible to figure out how much is used from model size and inference time. I think the model runs on the EDR robot itself. The EDR bot is custom Google hardware, and I had some trouble finding specs for it online.
RT1 for multiple robotics platforms
Remember that issue with lack of training data we talked about above? One way to get more training data in robotics is to use recorded sessions from other robots. The problem with this is that different robots have different dynamics. Their arms are different sizes, which means that you can’t just map task execution one-to-one for the robots.
Google explores this problem by using training data from another robot (a Kuka arm). This training data was collected for a different (unrelated) paper that Google wrote. They do a three experiments here:
train on just EDR data (EDR is the robot used for everything else in the paper)
train on just Kuka data
train on a combination (they use 66% EDR data and 33% Kuka data)
Just data from a different robot produces terrible results. RT1 can’t figure out how to adapt what it’s seeing to the other mechanisms. Data from just EDR does ok (22% performance on picking stuff from a bin). Data from both robots improves performance to 39% on that bin-picking task.
It’s very cool that the RT1 network is able to improve from seeing multiple robots do something. It seems obvious that using extra data from the EDR robot would have been even better, but that would also be much more expensive.
One thing I would have loved to see is more experimentation on the ratio of robot-types in training data. How much data do you need from the robot you’re actually using in order to get good performance. Some kind of trade-off curve between data from your robot and others (rather than just the two point values) would have been useful.
I’m also curious if having data from lots of robot types (instead of just two) would help. If it does, we could be entering a future where there’s one network you just download for any new robot you build. You then fine-tune on your custom robot and have high performance right away.
Long term planning
Since RT1 is intended to allow robots to perform simple actions, you need a higher level planner to accomplish larger goals. A task like “bring me a glass of water” would require actions like “go to the cabinet”, “get a glass”, “go to the sink”, etc. Google has previously worked on SayCan, which uses a large language model (like GPT) to decompose high level tasks into individual actions like this.
Google did explore using SayCan with RT1. They showed that it gets pretty good performance compared to a few other networks that have been used with SayCan. The success of long duration plans requires each individual step to go right, so it seems obvious that a model better at individual steps would succeed more at long term planning. I’m not sure the SayCan experiments that Google did show anything other than “yes, the thing we expect about long plan performance actually still works”.
Other thoughts
Since RT1 was trained only on camera images and text descriptions, it doesn’t seem to have memory. If you ask it to bring you chips, it can see if it has chips in its hand, or if you do. The current observations of the world tell it everything it needs to know about its next step in the task. I suspect that RT1 would struggle more on tasks that had “hidden state”, where recent camera images don’t contain everything it needs to know.
Since I don’t follow Google’s research very closely, I was pretty surprised by how much of RT1 was just plugging together other networks that Google had worked on. RT1 uses EfficientNet, FiLM, TokenLearner, etc. This composability is pretty cool, and makes me think that the hidden-state issue is likely to be solved by plugging RT1 together with someone else Google is already working on.
This also contrasts pretty strongly with GPT-3 (and OpenAI’s whole approach). There’s obviously a lot of truth the the “scale is all you need” aphorism, but it’s interesting to see people take a highly structured approach. I like this quite a bit, as I think it improves interpretability and predictability of the model.
I’m also curious how they deal with imitation learning’s problems. Imitation learning from pre-collected episodes often leads to a brittle distribution of actions. If the world doesn’t exactly conform to what the training episodes look like, the AI won’t be able to figure out how to recover. This is solved by things like DAgger by allowing the AI to query humans about recovery options during training. RT1 got pretty good performance, and it looks like they ignore this question entirely. I wonder why it worked so well. Maybe all the episodes started from different enough initial conditions that recovery ability was learned? Or maybe the tasks are short enough for this to not matter, and recovery is done at a higher level by things like SayCan?
By corrigibility, I mostly just mean that the AI wants to listen to and learn from people that it’s already aligned with. I don’t mean aligning the AI’s goals with a person’s, I mean how the AI interacts with someone that it thinks it’s already aligned with.
Corrigibility means that if people give it information, it will incorporate that information. The ideal case is that if people tell the AI to turn off, it will turn off. And it will do so even if it isn’t sure why. Even if it thinks it could produce more “value” by remaining on. One approach to this involves tweaking the way the AI estimates the value of actions, so that turning off always seems good when the human suggest that. This approach has issues.
Another approach is what’s called moral uncertainty. You allow the AI a way to learn about what’s valuable, but you don’t give it an explicit value function. In this case, the AI doesn’t know what’s right, but it does know that humans can be a source of information about what’s right. Because the AI isn’t sure what’s right, it has an incentive to pay attention to the communications channel that can give it information about what’s right.
A simple model might be
Moral uncertainty models values as being learned from humans
Because consulting a human is slow and error prone, we might desire a utility maximizing agent to learn to predict what the human would say in various situations. It can then use these predictions (or direct estimates of the value function) to do tree search over its options when evaluating action plans.
So far so inverse reinforcement-learning. The corrigibility question comes up in the following scenario: what does the AI do if it’s predictions of value and the human’s direct instructions conflict?
Imagine the following scenario:
the AI is trying to pursue some complex plan
it estimates that the human would say the plan will have a good outcome
it also estimates that the abstract value function would return a high utility from the plan’s outcome
but the human is screaming at it to stop
What should it do?
Obviously we want it to stop in this case (that’s why we’re yelling). How do we design the AI so that this will happen?
Off-Switch Game
Representing corrigibility in general is hard, so one thing that researchers have done is investigate a simpler version. One simple game that people have thought a lot about is the off-switch game. Figuring out how to make a super-intelligence pay attention to (and maintain functionality of) an off-switch is the minimum viable implementation of corrigibility. It’s important to note here that the off-switch is really just a signal; a single-bit communication channel from humans to the AI. Don’t get wrapped up in implementation details like “does it actually remove power?”
How do you design an AI that would actively want to pay attention to whether a human presses an off-switch?
As Hadfield-Menell and team show, an AI that is informed by a rational human observer would have incentive to listen to that observer. However, the less capable the human observer is, the less reason the AI has to pay attention to the human. Hadfield-Menell provide a toy problem and derive situations in which the AI would prefer to ignore the human.
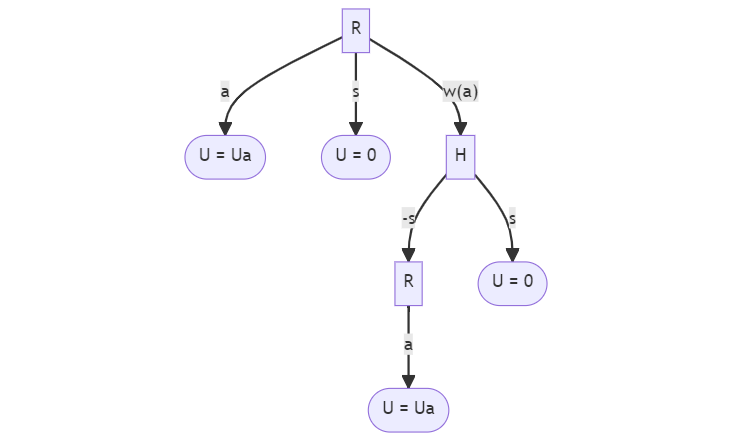
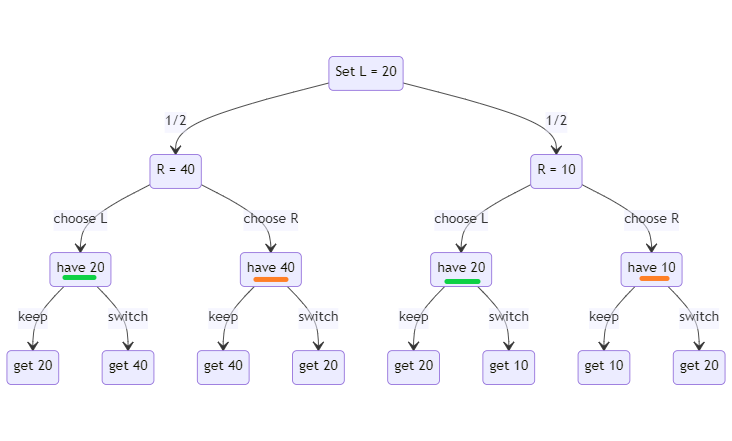
A game-tree formulation of the off-switch game.
In the diagram, the square “R” nodes indicate the AI doing something. The “a” arrow out of the “R” nodes indicate the AI taking an action. The “s” arrow indicates the AI turning itself off. The “w(a)” arrow indicates the AI waiting on the human to give advice about the proposed action. Each outcome has some utility, which might be U_a or 0. The value of U_a has an impact on what the AI chooses to do.
For any action, the AI can do it immediately, shut itself off immediately, or check with a human about whether to turn off or do the action. Hadfield-Menell then ask what needs to be true about the human and the AI for it to be incentivized to check in with the human. They define an incentive measure \Delta that represents the difference in expected value the AI would get when comparing waiting for the human to doing the next-best thing. If that incentive is positive, then the AI expects that it will do better by listening to the human. The incentive in their toy model is a function of three things: the human’s decision procedure, what the AI thinks the value is (represented by E[Ua]), and how confident the AI is in its prediction of value (sigma).
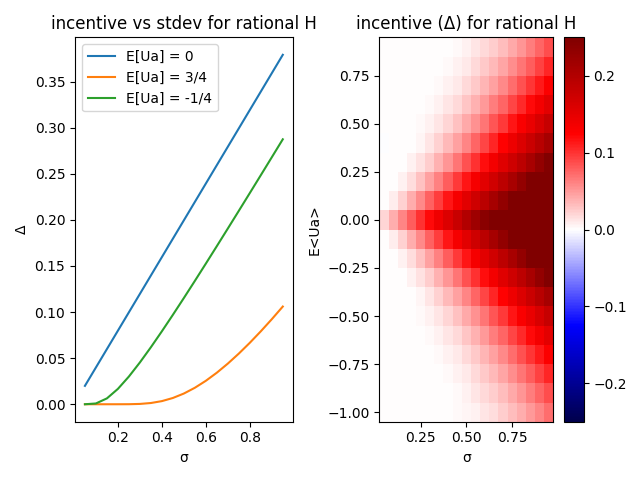
If the human is perfectly rational and always knows the true value of the action, then it always makes sense for the AI to ask. The AI could never do worse by asking the human, since it will always get an accurate answer. This is shown in the below plots (my reproduction of what I think was done in the paper). The incentive value is always non-negative, so the AI never loses out by waiting on the Human’s input.
Plots of the incentive for the AI to listen to a rational human
Unfortunately, we humans are not perfectly rational nor all-knowing about the results of given actions. If we were, our need for AGI would be much lower. How does the AI respond to irrational humans?
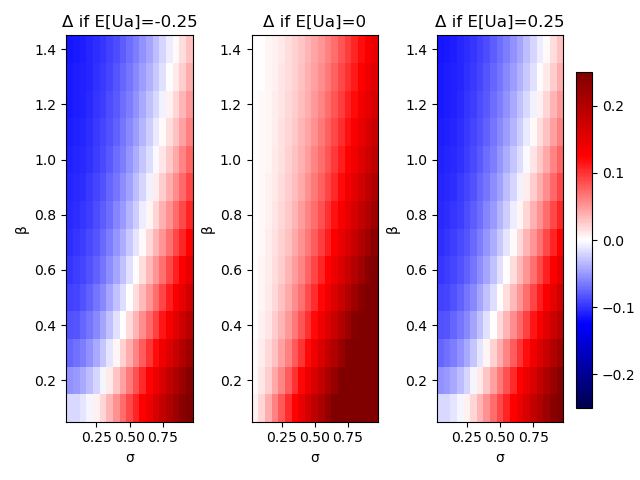
Hadfield-Menell model humans as noisy predictors of value using an exponential distribution. The more important the problem, the more likely HM expect the human to get the right answer (and vice versa). The pandemic has shown that this is a terrible model of humans evaluating potential actions, but lets just accept it and see what the AI would do.
In the below plots, blue indicates the AI expects negative value from asking the human in certain circumstances. White is neutral, and red is positive value. When the AI is very uncertain about what the human will say, the incentive for listening goes up.
Plots of the incentive for the AI to listen to an irrational human. Note the blue regions where the AI would ignore the human’s input.
The best alternative in the case on the left (where E[Ua] = -0.25) is turning off without checking in with the human. The best alternative in the case on the right (where E[Ua] = 0.25) is to simply take the action without waiting. In both left and right plots, there’s a sizeable region where the AI can do better by ignoring the human.
This shows that an AI would listen to the human unless its own estimate of human value (measured by the AI itself as having a low variance in action value) was quite high as in the red zones of the above plots. After learning to predict the value accurately, it would cease listening to a human. Their paper goes on to explore what the AI does if it (intentionally) incorrectly models the variance of the value. In addition to reducing overall value generated (see the paper), this violates our general principle to not rely on an AGI being ill-informed about the world to maintain safety. We therefore will ignore the idea of artificially increasing \sigma to make the AI listen to us.
An AGI that would ignore a human’s input might be worrying, but if you want to build a sovereign AGI then it’s to be expected. There’s no reason to build a sovereign if it never truly becomes sovereign. Once its knows enough, you want it to just do the right thing. If it just faithfully does whatever a human would do, then you’re just recreating all of the problems that humans have, but with additional translation difficulties (see e.g. lethality 20).
Updated Deference and discounted rewards
There is another worry that’s harder to see in a game like Hadfield-Menell’s. What if the AI reasons about the future like this:
the human wants to turn me off now because I suggested taking a low value action
if I stay on and keep learning, I’ll eventually know how to take actions that are so good they vastly make up for the minor negative of the currently suggested action
so I should ignore the human and stay on so that I can power up enough to achieve high value
This was Eliezer’s concern about moral uncertainty as a foundation of corrigibility. In order to investigate it using the Hadfield-Menell framework, we’ll have to add some complexity to the toy problem that they explored.
One intuitive response to this is that the human obviously wants to achieve their own value, and will try again with an AI that is more likely to accomplish it. Inasmuch as the AI actually supports the human’s values, it is only delaying achievement of its goal by shutting down. Given the potential enormous upside to doing well, an AI with proper reward discounting ( \gamma ) would prefer to be replaced (with a delay of n years) with another AI that is more likely to succeed (p(success)). The details of this argument depend upon the AI’s actual discounting rate, how likely it thinks it is to succeed, and how long it thinks the human will take to replace it. Let’s see if we can do any better without having to depend on a variety of free parameters turning out properly.
The HM off-switch game is really just a modified component of a reinforcement learning problem. In reinforcement learning, an AI will often do the following:
observe the current world-state: s
produce an action to take given the current world-state: a = \pi(s)
perform action a and return to step 1
The off-switch game of HM adds the following few steps:
2.1 estimate the value of taking the action – q _\pi (s, a) 2.2 decide whether to perform the action, wait for the human to evaluate the action, or turn off
The original off-switch game ignored steps 1 and 2 (observing the world and deciding on an action) in favor of simplicity. We need to think about them in order to model an AI that’s thinking about repeated plays. In particular, we want to think about how the AI estimates the value of taking an action. HM represent this value as U_a , but in a reinforcement learning context it’s often represented as q _\pi (s, a). This value is the sum of immediate rewards for all future actions, with some appropriate discounting factor:
In this case we have our discounting factor gamma to scale expected future reward. The reward from the direct action is scaled by \gamma^0=1 . The reward from the step after that is scaled by \gamma , the reward from the action after that is scaled by \gamma^2 . With \gamma below 1, this sum is a geometric series that converges for bounded R.
(One note about this more accurate game is that it allows the AI to model making actions with small immediate negative reward. This is desirable because exploratory actions may be expected negative in immediate reward and yet positive in long term value. In the original game, immediate and certain negative reward would induce the AI to turn itself off. The new game will have dynamics that depend heavily on how the human reasons about such situations.)
Eliezer’s argument rests on a couple of assumptions. The first is that the AI anticipates that it’s model will get better. In other words, it anticipates that its policy \pi (s) will produce actions with higher reward in the future than it does today. It also anticipates that it will become more confident in those actions. These anticipations are equivalent to anticipating E[Ua] increasing and \sigma^2 decreasing over time.
We saw in HM’s experiment with a model of irrational humans that if E[Ua]=q _\pi (s,a) is large, the AI needs a correspondingly higher uncertainty in its estimate for it to be worth listening to the human. We are unfortunately assuming both that E[Ua] gets large and \sigma^2 gets small. The AI will not listen to us in the future.
Will it listen to us right now? With a given discounting rate, maybe the sum of discounted rewards will be small enough to have it pay attention to our input in the short term?
Let’s get a better intuition for where this leads us. In this case we’ll represent each step’s reward as a Gaussian random variable, just as HM did. Instead of having a fixed mean and standard deviation, we’ll make these functions of time. Specifically, each will be a sigmoid function to represent the anticipation of the AI that it gets better at producing actions with high expected reward over time.
In this case, k represents the timestep. As time passes, the increasing k value will cause the expected value of each action to approach 1 and the standard deviation to approach 0. The AI will get arbitrarily close to maximum reward with minimum variance in the future.
Remember that value is q_\pi(s, a) above. Let’s ignore S_t and A_t in the above equation, since we’re assuming we know the reward distribution independently of individual actions. Let’s also assume continuous time. We then have a discounted reward expectation of
q_\pi(s, a) = \mathbf{E}\pi[\int{k=0}^{\infty}\gamma^kR_{t+k+1}dk]=\int\int \gamma^k \frac{1}{1+e^{-k}} N(\frac{1}{1+e^{-k}}, 1-\frac{1}{1+e^{-k}}) dk dr
Obviously the exact value here will depend on the discount rate, but the important thing to note is that this is a finite value. Wolfram Alpha will happily spit out values for you for whatever value of \gamma<1 that you want to try. That said, if the discount factor is large enough (say 0.8 or 0.9), the value of the action grows much larger than the reward from any single action is likely to be (even in the far future when the AI is smarter).
We can be more precise than just plugging values into Wolfram Alpha, though. Since R_{t+k+1} is a normal random variable, the sum over all k of R_{t+k+1} is another normal random variable with mean and variance given by the equation aR_1 + bR_2 \sim N(a\mu_{r1} + b\mu_{r2}, a^2\sigma^2_{r1} + b^2\sigma^2_{r2}) . This means our sum of discounted rewards will also be a normal distribution with mean and variance given by:
\mu_\Sigma = \int_{k=0}^{\infty} \frac{\gamma^k}{1+e^{-k}}dk and \sigma^2_\Sigma=\int_{k=0}^{\infty} \gamma^{2k}(1-\frac{1}{1+e^{-k}})dk
We can then use these values in our one-shot HM game to determine if the AI will ask the human for help. Again, the details depend on the value chosen for the discount factor. The key takeaway is that the expected value can be much higher than even the peak individual reward, and that the variance grows very slowly (that power of 2 in the \sigma_\Sigma equation really hurts).
Not only can we predict that AI won’t listen to us in the future when it knows more, we can also say that it won’t listen to us now because of that future prediction!
Realistic impacts of moral uncertainty
This seems to be the crux of Eliezer’s argument. Expecting high future value makes the AI willing to ignore present advice. While it seems airtight, there are a few details that make it less convincing. We saw one above related to how the human would obviously try again with a more capable AI if this one turned off, so discount rates impacted whether it was worth turning off.
Another issue is the assumption about improving performance of the AI over time. We assumed a sigmoid with increasing reward and decreasing variance on each timestep. This gave us an implicit independent relationship between the outcome of one action and the outcome of the next, but in the real world these are highly dependent variables.
Without a real model for how the AI learns and what actions it might have available to it, it’s hard to do better than the independence assumption mathematically. The most major issue is that the AI may end up in an unrecoverably bad state. It can expect that the mean of its reward will increase, but if it hits a tail outcome with highly negative reward then that could sink it’s future expectations. As a concrete example, assume that the AI values original artworks for some reason. If those artworks were destroyed, the AI will have permanently lost value. Sure it could recreate them, but those are then reproductions and not originals.
The AI doesn’t particularly need to know which actions could lead to unrecoverable loss. It just needs to believe that such things are possible. If the likelihood is high enough, it reduces the discounted future value of ignoring the human.
St. Petersburg and Moral Uncertainty
The problem is that our AI is willing ignore current negative utility in favor of high expected future utility. This is similar to the St. Petersburg Paradox.
In that paradox, a person is offered the chance to flip a coin. If the first flip comes up heads, they get $1. For every subsequent heads, the amount of money they get is doubled. After the first tails, the game ends and they don’t get any more.
The question is, how much would you pay to be allowed to play that game? Since there’s a possibility that you get 1 million heads in a row, you should be willing to pay an enormous amount. Even though the probability of those long runs of heads is low, the value from it is an astronomical 2 to the 1,000,000th power.
Intuitively though, it actually doesn’t make sense to pay millions of dollars to play this game. The most likely outcome is just a few dollars, not millions or billions. Why does our intuition conflict with the expected value of the game?
The answer is that the game is not ergodic. The expected value of a time series is not the same as the expected value of an ensemble. In other words, some people who play the game will get billions, but it probably won’t be you.
This is analogous to the AI that’s deciding whether to pay attention to a human yelling “stop”. Some AI might be able to access all that value that it’s predicting, but it probably won’t be this specific AI.
Making a corrigible agent
Having looked into the Hadfield-Menell paper in more depth, I still think that moral uncertainty will play a part in a fully corrigible AI. In order to do it, the AI will have to meet several other requirements as well. It will need to be smart enough not to play the St. Petersburg game. Smart enough to understand the opportunity costs of its own actions, and the probable actions of people with the same values as it. Smart enough to have a good theory of mind of the humans trying to press the switch. That’s a lot to ask of a young superintelligence, especially one that might not be quite so super yet.
The book itself is a collection of blog posts. There’s about 30 chapters, each one self-contained advice about how to address a certain aspect of raising a toddler. This is actually a great format for parents of toddlers. In that wide-eyed sleep-deprived state of pure stress, having a single short chapter to go to can be super helpful. Chapters range from how to deal with hitting, to food, to siblings. Some take the form of letters the author received, and her responses. Others are pure exposition.
While I found the specific solutions offered to be interesting and useful, what I really liked about the book was the underlying theory of child-rearing that each chapter instantiated. There’s a strong and coherent philosophy behind this book, and it’s only mostly similar to my intuitions after raising two toddlers.
I’d sum up the No Bad Kids philosophy as:
parents need to be leaders, in the best sense of the word
kids like boundaries, even if those boundaries causes them to have strong feelings
respect kids exactly as much as you would respect an adult (presumably an adult you like)
don’t expect more of kids than they’re able to give
Each of these guidelines is more controversial than it appears, and many popular child rearing books explicitly disagree with one or more of them. Some examples of advice I’ve been given that goes against these rules are:
talk in third person to reinforce language acquisition
push your kids beyond what they’re capable of, to help them develop new skills
let your kids lead all activities
and many more
One of the most thought-provoking pieces of advice from the book was around boundary setting and leadership. I’m used to letting my kids pretty much set the pace, and I’ll only redirect them if they’re doing something dangerous and destructive. This often means that they end up lollygagging, playing roughly with things, or screaming and shouting indoors. Since these things aren’t immediately dangerous or destructive, I’ll often let them keep going. My thought process is that if I let them set the pace, they’ll learn agency.
In the No Bad Kids paradigm, that’s exactly backwards. The idea is that I should be asserting specific and enforceable boundaries in those situations. Then if the kids don’t respect those boundaries, I physically stop the boundary from being crossed. An example would be taking toys away if they’re being used too roughly, or picking up the kiddo if they aren’t moving quickly enough towards the car.
I had been avoiding setting those boundaries because “it’s just my personal preference, they aren’t being dangerous” and “I want them to feel in control of their own life”. The problem is that I am a normal human person. Delays, broken toys, and constant loud noises can stress me out. If they just keep happening, my patience will wear thin. I have never blown up at my kid. What has happened is that I lose my cool and arguments turn into battles of will where I am stressed and frustrated.
No Bad Kids advises that I side-step that whole issue by setting boundaries for things I want, even if they aren’t safety issues. By setting boundaries earlier and enforcing them, I’m being respectful to my own preference and preventing myself from having to deal with things that try my patience. That’s good for my kids, because I then have enough patience to truly connect with them and be there with them. That connection is worth the temporary frustration they may experience when the boundary is asserted in the first place.
While this seems like it’s primarily an issue of leadership, it’s also an issue of respecting your kids like you would an adult. In general it’s best to assert boundaries with other adults early and clearly. We generally do this under the assumption that the adult will respect it and you won’t need to physically enforce it. This keeps the adult relationship healthy.
On the other hand, I know someone (an adult) who feels that asserting boundaries on other adults is rude. Instead of asserting the boundary, they’ll keep giving the other person a pass. This works right up until the point that my acquaintance loses their temper. Then they’ll cut the other person off from their life forever. Often the person being cut-off is surprised, because they never got any feedback that would imply they were even close to a boundary.
Imagine that situation, but instead of losing patience with an adult that you can cut off, it’s your own kid. You have to be there to support them, but suddenly you no longer even like them. That’s a nightmare scenario.
The other question is one of agency and leadership. The zeitgeist now (at least in my social circle) is for child-led parenting. Kids want to do X, we do X. Kids want to learn Y, we learn Y. Kids want to go at Z pace, that’s the pace we go at. The hope is that this teaches the child agency and gives them a sense of leadership in their own life. Won’t adding non-safety boundaries hem our child in and prevent agency from developing?
I think the key here is to separate agency from leadership. We want our kids to develop agency, but an agency that respects the autonomy and needs of others. By asserting boundaries, we are giving our kids safe regions to explore agency that everyone is comfortable with. Our leadership does not consist just in setting our own boundaries, it also consists of constructing environments for our kids that don’t tempt them outside of set boundaries. Hide the noisemakers, baby-proof the electrical outlets, put away delicate electronics. Then your kid can explore with full agency, without you constantly needing to say no.
This reminds me of leadership within companies as well. Managers want their reports to have agency. They want employees to be thinking of better ways to do things, solving problems early before they can grow large. In technical companies, managers want their employees to go out and learn what needs learning, not wait for the manager to intervene. That all needs to be done in a context that contributes to the team, which means employees need to respect the boundaries of others on their team and of the company as a whole.
I don’t always like corporate metaphors for family (in either direction), but this example helped me see how you could give your kids freedom and agency while still establishing your own boundaries.
So asserting boundaries earlier is critical. It gives parents the space they need to maintain sanity. It gives kids the leadership and guidance they need to understand their place in the world. How to do it, though?
No Bad Kids provides a few scripts for asserting these boundaries. For one thing, toddler attention can quickly shift to other things. You need to assert the boundary in the moment, or it gets much harder to communicate about. The book recommends that you notice when a boundary is about to be crossed, then simply say that you won’t let it happen. If necessary, do what it takes to interrupt.
One example is kids hitting their parents. If a kid tries to hit a parent, the parent can just say “I won’t let you hit me”. Then if the kid continues to hit, the parent can gently redirect the hands or hold them still. This avoids a lecture and confusing moralizing, and still communicates what the boundary is.
Of course, this requires the parent to know their boundaries well. You need to be able to respect your own needs, to articulate them simply, and to stand up for them. This is hard. Realizing this made me suddenly realize why people sometimes say they “aren’t mature enough for kids yet”. I had thought that excuse masked other feelings, but I now see the ways in which it can be straightforwardly literally true. That said, I also think kids give a great opportunity to learn those skills.
This book also renewed my appreciation for how much nuance there is in child rearing. A lot of advice sounds something like “respect the child” or “let the child lead the play”. Those are great in some situations and counterproductive in others. There is an underlying philosophy about what “respect” and “leadership” mean where the advice always makes sense. It’s not necessarily obvious though.
I often think that books for general audiences have too many anecdotes and examples. I want every book to be a math textbook. Give me the theory and the proof, and I’ll take it from there. With topics where people have an enormous amount of preconceived wisdom, I now see why anecdotes are so useful. They help the reader interpret “let the child be self-directed” in a way that doesn’t imply “don’t set any boundaries except for safety”.
While I think I’ve summarized the points of the book well here, I encourage people who are raising toddlers to actually go read the book to get the anecdotes.
Cuckoo’s Egg is a surprisingly readable description of Cliff Stoll’s quest to catch the hacker who stole $0.75 in computer time on his mainframe. The events in the story happened back in 1985 and 1986, and the book itself was published in 1989. As such, it’s a bit of a time machine into what technology and society looked like in the years before I was born.
i.
About 75% of this book is detailed descriptions of how various technologies work. These are usually tied in with understanding how the hacker is breaking into Stoll’s computers. As both a nerd and a history buff, these were mostly what I was reading the book for. If you don’t want to read three pages on what email is, written from the perspective of a technical person in the 1980s, this book isn’t for you.
The joy of reading about these old technical details is not in learning what “electronic mail” was. The main joy of the book is about reading history in reverse. Learning what normal parts of today were once surprising and new. This book helped me appreciate and understand the technologies that still work for us today.
And we do still use a lot of the technologies in the book today. I noticed myself judging Stoll for his argument ordering of ps -axu where I would use ps -aux. He talked about the Vi and emacs divide from the perspective of someone just witnessing it forming. Crucially, this book is one of the better explanations I’ve found for how hacking really works, and what penetrating a computer often looks like. Both the monotony of it and the use of zero-days.
Surprisingly for a book on the technical aspects of computer security, Stoll emphasizes social solutions to the problems. He focuses on the importance of trust, humans trusting other humans, to maintaining the usefulness of the internet. His concern with hackers is not just that they may destroy useful data or hurt people directly. He’s also concerned that degraded trust will cause people to stop posting useful things on the internet.
I think he was right about degradations in trust totally changing the nature of the internet. In the 80s, the internet was very much just a collection of computers that you could get accounts on and explore. These days the internet is almost universally seen as a collection of web pages. The underlying structure of computers talking to each other is still there, but everything has been locked down and secured. The infrastructure of the web (as distinct from the general internet) protects both servers and the general public. It’s probably much more interesting and useful than the internet that Cliff Stoll used at first, but I do feel a yearning for that open camaraderie he describes when talking about other internet users in the 80s.
ii
Another section of the book covers the story of Stoll coming to understand how various US government bureaucracies handled computer crime. This was an especially interesting topic given what I had read in Sterling’s book on the Hacker Crackdown. Sterling describes broad overreach and overreaction to kids just exploring. He describes law enforcement going out of their way to catch and punish anyone committing computer crimes, even if it’s a kid copying a $10 pamphlet from the phone company.
In contrast, Cliff Stoll discusses how he called up first the local police, then the FBI, then the CIA, then the NSA, and even the OSI. These groups ranged from totally uninterested to unofficially supportive. None of them could help him much until he had already found overwhelming proof of espionage, not just hacking. It took almost a year to really get any support from the FBI.
The events of the Cuckoo’s Egg take place in 1985 and ’86, while the Hacker Crackdown takes place in 1990. A large consequence of Cuckoo’s Egg itself was in making hacking and computer security something that got taken seriously. Hacker Crackdown spends a few pages discussing Stoll and his hacker, but it wasn’t until I read this book that I really understood the societal weight of those events.
iii
Finally, Cuckoo’s Egg spends just enough time talking about Stoll’s life outside of work that you get a bit of a sense for Berkeley and San Francisco in the 80s. Visions of ex-hippies having wacky parties are mixed with his musings on his relationship with his long-term sweetie. This turns into an extended discussion of how tracking the hacker down had changed Stoll’s perspective on government and on life. He goes from not trusting the government or thinking law enforcement has any redeeming qualities to actively supporting the CIA and FBI. He learns to see the complexity of the world, and in doing so finally grows into a responsible adult.
I found these personal sections of the book to be refreshing. They really made Stoll seem more like a real person, and not like some super-sleuth counter-hacker. I wouldn’t have read the book just for this, but I do think they added to the book and helped to flesh out some of the moral quandaries of youthful exploration, hacking, law enforcement, and personal responsibility.
These moral quandaries were also explored in Hacker Crackdown, but with a bit of a different conclusion. Cliff Stoll found a hacker who was intent on stealing American technical and military secrets to sell to the KGB. The Hacker Crackdown of 1990 mostly found some kids who were stretching their skills and showing off for each other.
It’s hard for me to draw firm personal conclusions here. Both of these books moved me more towards thinking that law enforcement was important and that black hat hackers are doing active damage even when not deleting or destroying anything. With the benefit of hindsight, I think Stoll’s view underestimated the use of security over trust. I also very highly value a freedom of exploration and thought that I learned from the hacker culture of the early 2000s.
The book includes some stories of Stoll’s younger years in which he seems like very much a prankster in the mold of a white hat hacker. It seems clear that he sees value in a kind of youthful exploration and pranking. I wonder what he’d say about the Hacker Crackdown, and whether that changed his mind about where we as a society should set the dial with law enforcement.
Suppose I show you two envelopes. I tell you that they both have money in them. One has twice as much as the other. You can choose one and keep it.
Obviously you want the one that has more money. Knowing only what I’ve told you already, both envelopes seem equally good to you.
Let’s say you choose the left envelope. I give it to you, but before you can open it I stop you and tell you this:
You’ve chosen one envelope. Do you want to open this one or switch to the other one?
You think about this, and come up with the following argument:
I chose the left envelope, so let’s assume it has L dollars in it. I know that the other envelope has L/2 dollars with 50% probability and 2L dollars with 50% probability. That makes the expected value of switching envelopes 1/2(L/2) + 1/2(2L), or 5/4 * L. So it does make sense for you to switch to the right envelope.
The decision matrix for this might look something like:
R = L/2
R = 2L
Keep L
L
L
Switch R
L/2
2L
But just as you go to open the right envelope, I ask you if you want to switch to the left. By the same argument you just made, the value of the left envelope is either R/2 or 2R and it does make sense to switch.
Every time you’re just about to open an envelope, you convince yourself to switch. Back and forth forever.
The Real Answer
Obviously the original reasoning doesn’t make sense, but teasing out why is tricky. In order to understand why it doesn’t make sense to switch, we need to think a bit more about how the problem is set up.
Here’s what we know:
L is the value of money in the left envelope
R is the value of money in the right envelope
R + L = V, a constant value that never changes after you’re presented with the envelopes
L = 2R or L = R/2
There are actually two ways that I could have set up the envelopes before offering them to you.
Problem setup 1:
choose the value in the left envelope
flip a coin
if tails, the right envelope will have half the value of the left
if heads, the right envelope will have twice the value
Problem setup 2:
choose the total value of both envelopes
flip a coin
if tails, the left envelope has 1/3 of the total value
if heads, the left envelope has 2/3 of the total value
Both these formulations result in the same presentation of the problem, but they need different analysis to understand.
Problem Setup 1: L = 20
Let’s make things concrete to make it easier to follow. In problem setup one we start by choosing the value in the left envelope, so let’s set it to $20. Now the game tree for the problem looks like this:
We’re showing the true game state here, but when you actually choose the Left envelope you don’t know what world you’re in. That means that, once you choose the left envelope, you could be in either of the “have 20” states shown in the game tree (marked in green). Let’s look at the decision matrix:
R = L/2
R = 2L
Keep L
20
20
Switch R
10
40
In this case, the outcomes are which one of the two green-marked worlds you’re actually in. At the time you’re making this choice, you don’t know what L is. We’re filling in numbers from the “god-perspective” here.
Now the math here matches what we saw at first. The benefit of switching is 10/2 + 40/2 = 25. The benefit of staying is 20. So we should switch.
Once you switch, you’re offered the same option. But in this case the decision matrix looks different. You don’t know which of the orange-marked R states you’re in, but they’re both different values:
L = R/2
L = 2R
Keep R
40
10
Switch L
20
20
Now it makes sense to keep R! The reason is that the “R” value is different depending on which world you’re in. That wasn’t true of L because of how the envelopes were filled originally.
With this problem setup, it makes sense to switch the first time. It doesn’t make sense to switch after that. There’s no infinite switching, and no paradox.
In fact, it only makes sense to switch the first time because we “know” that the Left envelope has a fixed amount of money in it (the $20 we started the problem with).
If instead we didn’t know if the fixed amount was in the left or the right, we would be equally happy keeping or switching. That’s because both options would give us a 50/50 shot at 5/4 the fixed value or the fixed value.
Problem Setup 2: V = 60
In the second setup, the questioner choose the total value of both envelopes instead of choosing how much is in one envelope. Let’s set the total value to be $60. That means that one envelope will have $20 and the other will have $40, but we don’t know which is which.
The game tree for this problem is different than the last one:
Now assume that I choose the Left envelope, just like before. In this case I don’t know which of the two possible worlds I’m in. So I don’t know if I have $20 or $40. This makes the decision matrix look like this:
R = L/2
R = 2L
Keep L
40
20
Switch R
20
40
In this case it’s very clear that the situation is symmetric from the start. The “L value” is different depending on whether you’re in the “R = L/2” or “R = 2L” world. There’s no reason to switch even once.
The fundamental mistake
The fundamental mistake that originally led to the idea of a paradox is this: we assumed that the amount of money in the left envelope that you chose was fixed.
It is true that once you choose an envelope, there’s a certain unchanging amount of money in it.
It’s also true that the other, unchosen, envelope either has twice or half the amount of money in it.
It is not true that the amount of money in your envelope is the same regardless of whether the other envelope has double or half the amount. You just don’t know which world you’re in (or which branch of the game tree). The expected value calculation we did at first used a fixed value for what was in your current envelope. The key is that if you’re making assumptions about what could be in the other envelope, then you need to update your assumption for what’s in your current envelope to match.