The holodeck problem is closely related to wireheading. While wireheading directly stimulates a reward center, the holodeck problem occurs when an agent manipulates its own senses so that it observes a specific high value scenario that isn’t actually happening.
Imagine living in a holodeck in Star Trek. You can have any kind of life you want; you could be emperor. You get all of the sights, smells, sounds, and feels of achieving all of your goals. The problem is that the observations you’re making don’t correlate highly with the rest of the world. You may observe that you’re the savior of the human race, but no actual humans have been saved.
Real agents don’t have direct access to the state of the world. They don’t just “know” where they are, or how much money they have, or whether there is food in their fridge. Real agents have to infer these things from observations, and their observations aren’t 100% reliable.
In a decision agent sense, the holodeck problem corresponds to the agent manipulating its own perceptions. Perhaps the agent has a vision system, and it puts a picture of a pile of gold in front of the camera. Or perhaps it just rewrites the camera driver, so that the pixel arrays returned show what the agent wants.
If you intend on making a highly capable agent, you want to be able to ensure that it won’t take these actions.
Decision Theoretic Observation Hacking
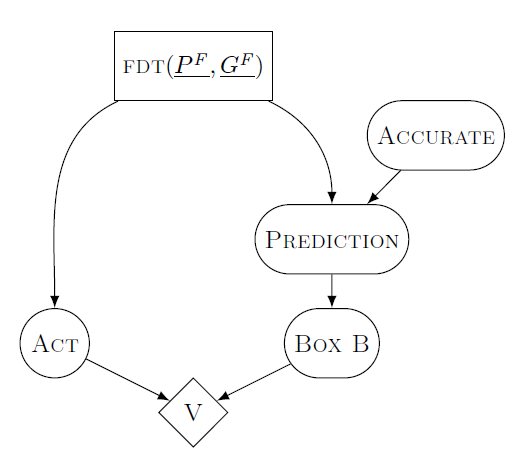
A decision theoretic agent attempts to select actions that maximize its utility based on what effect they expect those actions to have. They are evaluating the equation p(state-s, a -> o; x)U(o) for all the various actions (a) that they can take.
As usual, U(o) is the utility that the agent ascribes to outcome o. The agent models how likely outcome o is to happen based on how it thinks the world is arranged right now (state-s), what actions are available to it (a), and its observations of the world in the past (x).
The holodeck problem occurs if the agent is able to take actions (a) that manipulate its future observations (x). Doing so changes the agent’s future model of the world.
Unlike the wireheading problem, an agent that is hacking its observational system still values the right things. The problem is that it doesn’t understand that the changes it is making are not impacting the actual reward you want the agent to optimize for.
We don’t want to “prevent” an agent from living in a holodeck. We want an agent that understands that living in a holodeck doesn’t accomplish its goals. This means that we need to represent the correlation of its sense perceptions with reality as a part of the agent’s world-model M.
The part of the agent’s world-model that represents its own perceptual-system can be used to produce an estimate of the perceptual system’s accuracy. Perhaps it would produce some probability P(x|o), the probability of the observations given that you know the outcome holds. We would then want to keep P(x|o) “peak-y” in some sense. If the agent gets a different outcome, but its observations are exactly the same, then its observations are broken.
We don’t need to have the agent explicitly care about protecting its perception system. Assuming the model of the perception system is accurate, and agent that is planning future actions (by recursing on its decision procedure) would predict that entering a holodeck would cause the P(x|o) to become almost uniform. This would lower the probability that it ascribes to high value outcomes, and thus be a thing to avoid.
The agent could be designed such that it is modeling observations that it might make, and then predicting outcomes based on observations. In this case, we’d build p(state-s, a -> o; x) such that prediction of the world-model M^{a\rightharpoonup} are predictions over observations x. We can then calculate the probability of an outcome o given an observation x using Bayes’ Theorem:
P(o|x) = \frac{P(x|o)P(o)}{P(x)}.
In this case, the more correlated an agent believes its sensors to be, the more it will output high probabilities for some outcome.
Potential issues with this solution
Solving the holodeck problem in this way requires some changes to how agents are often represented.
1. The agent’s world-model must include the function of its own sensors.
2. The agent’s predictions of the world should predict sense-perceptions, not outcomes.
3. On this model, outcomes may still be worth living out in a holodeck if they are high enough value to make up for the low probability that they have of existing.
In order to represent the probability of observations given an outcome, the agent needs to know how its sensors work. It needs to be able to model changes to the sensors, the environment, and it’s own interpretation of the sense data and generate P(o|x) from all of this.
It’s not yet clear to me what all of the ramifications of having the agent’s model predict observations instead of outcomes is. That’s definitely something that also needs to be explored more.
It is troubling that this model doesn’t prevent an agent from entering a holodeck if the holodeck offers observations that are in some sense good enough to outweigh the loss in predictive utility of the observations. This is also something that needs to be explored.