Observe, orient, decide, act. Then do it all again.
This loop, known as the OODA loop, was originally developed by Colonel John Boyd to describe why American fighter pilots in Korea out-flew MIGs with better top speeds and altitudes. The American jets could respond faster, so even though they couldn’t go as fast they could be agile enough to take out the enemy. The American pilots (because of their jet design) had a short OODA loop.
After the Korean war, Colonel Boyd used what he’d learned to push through the development of the F-16. He then spent the rest of his life applying the idea of the OODA loop to everything: grand strategy, procurement, the meaning of life.
In spite of spending his life popularizing the OODA loop, he didn’t actually write much. If you look for primary material on the loop, you get this 400 page PDF of transparencies from 1987. While those slides are interesting, they’re almost exclusively concerned with grand strategy and military doctrine.
There’s a lack of clear primary sources about OODA loops applied to anything other than warfare. Despite this, there’s still a lot of interest in OODA loops for things like procurement, human psychology, and even (somewhat) in robotics. Most of what you can find seems to be people riffing on what John Boyd had done originally, so I’m going to do the same thing by looking at Digital Signal Processing through the lens of the OODA loop.
Observe = Sample
Signal processing is largely seen as being concerned with what you do after you have a signal, but you always need to start with how the signal is gathered. To observe a signal well you need to think about questions such as
what type of signal am I measuring (acceleration? radio?)
what are the smallest and largest signals you need to resolve (to determine quantization and gain)
There are whole courses taught to help people think about and answer these questions.
Orient = Transform and Filter
Once you have your signals, you need to put them in a usable format. The orient stage of the OODA loop is concerned with learning what you can from what you’ve observed, which in DSP terms means removing noise, transforming to useful domains, etc.
This is the heart of signal processing. Most of what you may think of as core signal processing falls in this step. All of the various types of transforms (Fourier, wavelet, etc.) are ways of viewing a signal in a more useful format. By choosing the domain in which the signal makes the most sense, you make it easier to pick out what’s important and ignore what isn’t via filtering.
The Kalman filter is another good example of this. One of the first steps of a Kalman filter is to apply a measurement matrix to your incoming signals. This measurement matrix transforms your sensor data into a domain that’s actually useful to you. You can then combine this transformed data (often in a state-space format) with what you already know to come up with a precise estimate of your current orientation (aka state).
Deciding and Acting
Beyond signal processing, you get into questions about what you want your signal for and what to do once you have it. These are questions that often lead into other domains, such as communications theory, control theory, and robotics.
Communications
In communications, you’re just sending signals back and forth to transmit data. In this case, your decision stage ends up being to determine what bits were sent. This is done through some combination of thresholding transformed signals, error corrective coding, etc. Your act loop may be to simply send a signal back.
Robotics
One of the pre-dominant paradigms of robotics prior to the 1980s was called the Sense-Plan-Act loop. The loop is similar to Boyd’s OODA loop, and the final step is the same in both. The three steps of observe-orient-decide are smashed into only two steps of sensing and planning here.
While I haven’t seen anyone argue this explicitly, the way the Sense-Plan-Act loop is used makes me think that the Orient and Decide steps are combined into a single plan step. For simple problems this seems straightforward, but in complex problems the orient step can be much more difficult than the decide step. If a robot knows what is going on around it, planning and deciding gets much easier.
For example, it seems like much of the difficulty in the self-driving world is actually observing and orienting. Planning and deciding for a self-driving car may be much easier. Route planning has been a solved problem for a long time, there are clear legal rules for how a vehicle must behave in certain conditions, and vehicle dynamics are well studied for cars on paved streets.
Just thinking about things as “planning” doesn’t necessarily prepare a designer to focus their efforts on what is likely to be difficult in robotics.
That said, the robotics state-of-the-art has moved on from both Sense-Plan-Act and OODA. Most cutting edge robots these days run ROS, which is a microservices architecture. ROS runs many different nodes in parallel, each gathering data and emitting outputs constantly. All of the steps of an OODA loop are performed, but not really in a loop at all (though you could view each ROS node as implementing an OODA loop of its own).
OODA loop is orienting on its own
I’m personally interested in the OODA loop in large part because it guides optimization during systems design. By explicitly breaking a problem into those domains, it makes clear what you’re trying to do with your sampling, your filtering, and so on. If you’re actively thinking about the OODA loop when you need to be making a decision, it might already be too late for it to help you. The time to use the OODA loop is when you’re deciding how to decide.
By thinking about your procedure through the lens of the OODA loop, you can recognize if you’ve sufficiently supported each element of the loop. This is the main reason that Sense-Plan-Act in robotics isn’t as good. It doesn’t adequately separate the sensing or planning from the very important step of orienting.
Venkatesh Rao talks a bit about this use of the OODA loop to do meta-planning here, but he seems to focus too much on meta-orienting and not enough on orienting during your mission.
In general I think the ROS paradigm of always executing microservice nodes that exchange information makes the most sense for real-time applications that have a lot of complexity. What the OODA loop can do is point you at possible node-types that you’re missing.
LiDAR sensors are a popular choice for robotic localization and mapping. How do you convert LiDAR data into a map that your robot can use to get around? Let’s explore how the LOAM algorithm does this.
Maps generated with LiDAR are a critical part of modern robotics.
LiDAR sensors are very popular in robotics, and work a lot better than cameras for localization and mapping. This is largely because you get the distance to everything the LiDAR sees automatically. With cameras (monocular or stereo), you have to do a lot of math to figure out far away things are and whether two things are spatially separated.
How are LiDAR actually used though? Once you have a LiDAR, how do you convert the data it spits out into a map that your robot can use to get around? One of the more popular algorithms for this is LOAM (LiDAR Odometry and Mapping). There are a few different open source implementations, but the most popular seem to be A-LOAM and Oh My Loam. I’m thankful to both of them for helping me to understand the paper.
Let’s dive into how LOAM works.
Note that some of the details of the algorithm are slightly different depending on what implementation you’re looking at, and the below is just my understanding of the high level algorithm.
Point Clouds
Before understanding how LOAM works, let’s learn a bit more about LiDAR data in general. The most popular way of storing LiDAR data is as a Point Cloud. This is simply a vector of the 3D points the sensor returns. In general, a LiDAR will return some measurements of azimuth, elevation, and distance for each object relative to the LiDAR itself. From these, you can calculate the X, Y, and Z positions of stuff in the real world. A point cloud is just a collection of these points, and if you’re using something like the Point Cloud Library then it will come along with a lot of utilities for things like moving the points around in space, registering points to new reference frames, and controlling the density of points in space.
These functions to shift points around are critical, because your LiDAR is going to be moving as you map. Every point that comes out of your sensor is defined in the reference frame of the sensor itself, which is moving around in the world. To get our map, we’ll want to to be able to take a point that’s defined relative to a sensor and shift it to where it should be in some fixed world plane.
We can use some functions from PCL to shift those clouds, but before that we need to figure out how they should shift. We do this by using LOAM to calculate how the sensor has moved between different LiDAR frames.
Usually point clouds are assumed to be unordered. We’re going to stick some additional information into our cloud before using it. Specifically, we’re going to keep track of which laser the data came from. We do this because most LiDARs have different azimuth resolution than elevation resolution. Velodyne’s VLP-16, for example, has 0.2 degrees of resolution in azimuth and 2 degrees of resolution in elevation. LOAM uses points differently if they’re aligned in the high resolution direction, and by tracking which laser the points came from we can inform LOAM about which direction is the high resolution direction.
LOAM finds features along the direction of a LiDAR’s output where the points are close together (along the Y-axis in this picture).
Maps
I’m apparently old now, because when I hear the word map I think of one of those fold-out things we used on road trips when I was a kid in the pre-smartphone era. The kind of map that takes up 10 square feet and covers the entire continental US. These road maps are abstract pictures of the world with included semantic meaning. They have labels. You can see what places are cities, where national parks are, and figure out if you can make it to the next rest stop.
When people talk about SLAM maps, they’re not talking about this kind of thing. The kind of map produced by LOAM and other SLAM techniques doesn’t have any semantic meaning. You could have a robot map your whole house, and LOAM wouldn’t be able to tell you where your kitchen was or the distance from your bedroom to the bathroom. What the produced map can tell you is what the 3D geometry of your house looks like. What places can the robot navigate to, as opposed to places that are occupied by your favorite chair.
The lack of semantic meaning for SLAM maps tripped me up when I was first learning about them. I kept seeing pictures of LiDAR points projected in space, then asking where the map was. The projected LiDAR points were the map! If you want to know what room has the oven, if you want semantic meaning, you’ll have to run your map through a higher level process that recognizes things like ovens (people are working on it).
The LOAM algorithm is going to take in point clouds generated by LiDAR as the sensor moves through space. Then LOAM is going to spit out one big point cloud that represents the geometry of the whole space. This is enough for a robot to avoid hitting things, plan routes between two points, and measure the distance between things (but it won’t know what those things are). In order to collate the series of point clouds the sensor spits out into one big map, LOAM needs to do two things:
Figure out how the LiDAR has moved in between one scan and the next
Figure out what points to keep in the map, and move them all to the right position relative to each other
These two steps are the L and the M in SLAM. By using sensor data to figure out where the robot is (localization), subsequent sensor readings can be aligned with each other to create a full map. LOAM does the localization part via LiDAR odometry. In other words it figures out from comparisons of one cloud to the next how the sensor has moved between when those clouds were captured.
Odometry
Doing odometry just means that you calculate the relative locations of the sensor given two point clouds. This gives you the motion of the robot between when the point clouds were made (also called ego-motion).
People are pretty good at looking at two pictures and estimating where they were taken from, but making a computer do this is pretty complicated. The (non-ML) state of the art is to find distinguishing points in the image (or point cloud). If you find the same distinguishing points in your second frame, you can use the difference in position of the point in the two scans to figure out the location difference of the sensor. This depends on a few different assumptions:
interest points won’t get confused for each other (at least not very often)
interest points don’t move around (so don’t use a dog in the frame as an interest point)
With LOAM, we’ll just assume that there aren’t any people, pets, or other robots in the scene. That satisfies assumption 2. How do we make sure that the distinguishing points won’t get confused with each other? And what is a distinguishing point anyway?
Feature Points
Distinguished points in an image or point cloud, generally referred to as feature points, are individual points in an image or point cloud that you can identify using local characteristics. For an image, they’re individual pixels. For a point cloud, individual laser returns. What makes them good features is that the other points around them have distinct spatial or color characteristics. Different algorithms (such as SIFT or SURF in camera-vision) use different characteristics. LOAM’s characteristic of choice is something they call curvature. By looking at how much the points curve through space, LOAM can identify flat planes (like building walls or floors) and edges (like table edges or places where one object is in front of another).
LOAM’s curvature measurement is calculated by looking only at points that are from the same “scan”. In this case, a scan means from the same laser and the same revolution. For a Velodyne, one revolution of the device produces a single set of 16 scans (or up to 128 if you have the expensive one). By only examining points in the same scan, LOAM’s curvature knows that the points should have the same angular distribution and lie in a plane (though that plane may be skew to X/Y/Z dimensions that define your world).
To calculate curvature, you pull all the points out of your incoming point cloud that came from the same scan. Next, you sort these spatially. You can get this spatial sorting by just looking at when the points were reported by the sensor, you don’t actually have to do any geometry for this step. For example, if you’re looking at circles reported by a single laser in a VeloDyne as your scan, then you can just order the points by the time they come in and have a spatial ordering as well.
After the points are ordered spatially, you calculate the curvature of every point. This curvature is calculated using only the 5 points on either side of the point you’re looking at (so 10 points plus the center point). You look at how far each nearby point is from the one you’re looking at, and sum those distances. High curvature points will have a high sum, low curvature points will have a low sum. There’s a pretty good code sample for this in the Oh My LOAM repo.
Not every curvature point will be considered to see if it’s a good feature. In particular, the following points are filtered out:
points that are on a surface that’s almost parallel to the laser beam
points that are on an edge that could be occluding something else
On the left, point B is ignored because it’s on a surface almost parallel to the laser. On the right, point A is filtered out because we can’t tell if it’s an edge or just occluded by B.
After being calculated, curvature values are sorted. Maximal curvature points are then selected as edge features and minimal curvature points are selected as plane features. Since it’s possible that all the maxima (or minima) are in one place, the scan is split into four identically sized regions. Then each region can provide up to 2 edge points and 4 plane points. Curvature points are selected as features only if they are above (below for planar points) a set threshold.
At the end of this procedure, you should have two distinct point clouds: the edge cloud and the flat cloud. (In LOAM software, there’s some terminology overlap. The words “surface”, “flat”, and “plane” all generally refer to the same set of points. Similarly, “edge” and “corner” both refer to the same set of points. I’ll use these terms interchangeably)
Correspondences
The first time you get a point cloud out of your sensor, you’ll just calculate a bunch of features and fill up an edge cloud and a flat cloud. The second time, you’ll have an old frame to actually compare the new features to. Now you can do odometry by comparing the new features to the old features. If you compare two lidar clouds to each other, you can calculate how the sensor moved between those frames, which is called the transformation.
For each feature point in your current edge and flat clouds, you find the nearest point in the the prior edge and flat clouds.
Finding correspondences is kind of tricky, and it involves repeatedly trying to find the best correspondence. This is done using an algorithm called Iterative Closest Point (or ICP).
In LOAM’s ICP, you do the following:
match corners between this frame and the last one using a guess-transform
match surfaces
using those matches, revise your transformation from the current frame to the last one
figure out how good the guess-transformation is, and improve it
repeat 3&4 until you have a good enough transformation
Matching points
Matching points is done by looking at each point in the edge cloud (or flat cloud and, for each point:
guessing at how to transform it to the pose of the prior frame
then finding the closest point to where your corner would be in the prior frame’s corners.
Guessing how to transform the point you’re looking at is tricky. This is basically the transformation you want to find anyway, that’s why you’re finding the correspondences in the first place. Finding correspondences is therefore a game of guess and check. To speed things up, we’ll make the best guess we can: the transformation between this frame and the last one is the same as between the last and the one before that. In other words, we think the robot is moving in a fairly consistent way. That’s not true, but it’s a good start assuming we’re sampling lidar frames fairly quickly.
If we don’t have a prior transformation to use as our guess, we can just assume that there’s been no motion (so we’d use an identity transformation).
After we’ve done our transformation of our candidate point to where it would have been before we moved, our next step is to find it’s corresponding point from the last cloud. This can be done using any nearest neighbor algorithm (kNN is a good choice).
For the corner points, we actually find the two nearest points to our candidate. You can draw a line through any two points, so by finding the nearest two from the prior frame we can evaluate whether our new point is on that same edge line. We don’t care if our new point is exactly the same as the prior points (it probably won’t be the same spot in space). We just care that it’s looking at pretty much the same edge that the prior ones were looking at.
We end up doing the above process for every edge point we found, comparing them to the prior frame’s edge points.
Then we do the process for every flat point we found, comparing them to the prior frame’s flat points. For the flat points, we actually find the nearest three points in the prior frame’s set of flat points. This is because you can draw a plane through any three points, and we want to see if our new candidate flat point is on the same surface (not necessarily if it’s the exact same spot in space as a prior point).
We’ll need the following information for each point going forward:
the point position in the current lidar frame (not adjusted using our guess-transformation)
the corresponding points (for the line or plane) in the last lidar frame
the transform we used to find the correspondence
Now we just need to know how good our candidate transformation was.
Evaluating the Match
We now have a list of points and the things we think they match to (lines or planes). We also have a single transformation that we think we can apply to each point to make them match. Our next step is to update that transformation so that the matches we think we have are as good as possible.
The update step for most open source implementations that I’ve seen is done using the Ceres Solver. Improving the transformation is formulated as a non-linear least squares optimization problem. The Ceres library is used to solve a least-squares optimization using the Levenberg-Marquardt algorithm.
The optimization being solved by Ceres is the distance between the correspondence points and the new lidar points that are corresponded to, after transforming the latter. The solution to this optimization problem is a transformation, and if our original guess was good then the solution will be pretty close to our guess. Either way, we’ll use the solution given by the Ceres Solver as our new guess for the transformation.
Refining the candidate transform
The sections we just saw for correspondences (finding the correspondences, optimizing the guess-transform) were just a single iteration of the Iterative Closest Point algorithm. Once you’ve done this once, your guess transform should be better than it was.
With a better guess transform, you could probably get better initial correspondences, which would lead to a better optimized transform. So we just repeat the whole process a few times.
Ideally, after you iterate this process enough the guess-transformation stops changing. At that point, you can be pretty sure you know how the sensor moved between the last frame and this frame. Congratulations, you’ve just performed odometry.
Now throw away the old point cloud and use your new point cloud as the comparison point once the next frame comes in. Repeat this process ad-nauseum to track how the robot moves over time. The odometry pipeline can happen in its own thread, completely independently of any mapping.
Mapping
Figuring out how the robot moves is useful, but it would be even more useful to have a complete voxel style map of the environment the robot moves through. The output of the odometry step is the single-step transform between one LiDAR frame and the next, and a cloud of feature points used to calculate that transform.
You can use that single-step transformation to update a “global transformation” that would place the point cloud relative to the robot’s starting position. The naive thing to do is to transform the feature points from the odometry step using that global transform, and then just save them all into the same point cloud. You’d think that doing this would result in the voxel grid you want, but there are some hiccups.
Odometry is optimized to be fast, so it only compares incoming LiDAR frames to the data in the immediately prior frame. That’s useful for getting a pretty good estimate of how the robot moves from frame to frame, but it’s going to be inaccurate. You only have one frame’s worth of points to compare with when you’re generating your odometry transform, so the closest points you use during ICP may not be all that close. Instead of using odometry output clouds directly for a map, we can run ICP a second time on a larger set of points. That let’s us refine the position of the new points before inserting them, resulting in a much more accurate map.
The reason we don’t do this step with odometry is, again, because odometry needs to be fast. The original LOAM paper runs odometry at 10x the speed of mapping. The Oh My Loam implementation just runs mapping as fast as it can, but then ignores any LiDAR points coming from the odometry stage while it’s processing. This means that it silently drops some unknown number of LiDAR points and just accepts incoming data when it’s able to handle it.
The mapping stage is almost the same as the odometry algorithm that we went over above. Here are the differences:
the candidate transform used in the first stage of ICP is the output of odometry (so we have a pretty good starting transform)
instead of comparing each incoming point to a single line or surface in the map (as odometry does), the map grabs a bunch of nearest neighbor points to compare to. The exact number is a configurable parameter, but by comparing to a bunch of points you can get a better idea of the exact geometric feature your incoming point belongs to
the optimization criterion for Levenberg-Marquardt is tweaked a bit to account for the additional points (item 2)
instead of only having a single LiDAR frame to look for neighbor points in, you can look for neighbors in the entire map
In practice, you actually take a sub-section of the map to look for your neighbors in to speed things up. No need to look for neighbor points a quarter mile away if your LiDAR range is only a few hundred feet.
Other than the above differences, the ICP algorithm proceeds almost identically to the odometry case. Once you have a fully refined transformation for the incoming points, you can use PCL to move the point to where it should be in space. This amounts to making its location be relative to the starting point of the robot’s motion, rather than relative to the LiDAR position when the point was detected. Then the point is inserted into the map.
The map itself is a collection of the surface and edge points from prior LiDAR frames. A lot of those points are likely to be close to each other, so the map is down-sampled. This means only points far enough away from other points are stored. In the paper, they set this distance as 5cm. The points themselves are stored in a KD-tree, which is a fast way of storing point clouds.
Two great tastes that taste great together
By doing odometry as close to real time as you can, you can track how your robot is moving through space. By doing a separate mapping stage that takes that odometry information into account, you can spend a lot of time making an accurate map without sacrificing your position estimate. Separating these tasks makes them both perform better.
In particular, odometry is important for things like motion planning that may not need access to the map. You can’t stop odometry while you wait for your map to compute. But odometry by itself can be very noisy, and you wouldn’t want something that needs a map depend only on lidar-odometry information for environment estimates.
There are a lot of ways to improve on this type of algorithm. One of the more obvious ones is to supplement your odometry stage with another sensor. If you have an IMU measuring accelerations, you can use those seed your initial transform estimate in your lidar-odometry step.
Hacker Crackdown is an interesting book. It’s been about 30 years since the events of the book occurred, and the book itself has fed into a cultural understanding of what hackers are and what they do. I’ve been hearing about the book for years, and picked up a copy way back when I was in high school and attending 2600 meetups. In spite of that, I never actually read it until last year.
My experience of the book was surprising. I had thought that it was going to be a uniformly positive account of hackers, and uniformly negative about the police who cracked down on them. Ever since my 2600 days, the hacker ethos has appealed to me. Exploring complicated systems to figure out how they worked, figuring out ways to exploit them, but doing it all with a conscience. Basically I wanted to be the kind of hacker that dates Angelina Jolie.
I went into the Hacker Crackdown with the assumption that it would validate all my biases and generally make me feel good about my pseudo-hacker roots. And it did. There’s a lot in the book about exploration, about figuring things out, about the hackers of yesterday becoming the inventors and engineers of today.
But that’s not all the book is about. It’s also about computer criminals, distinct from those who seek to understand a system. It’s about the police who hunt both types of hacker, and sometimes find it difficult to tell the difference.
The hacker crackdown itself was a set of police actions taken in 1990. Several phone phreaks and hackers had been invading Bell telephone systems, and had stolen a critical document that (claimed Bell) could let them destroy the 911 system. The police were called, the secret service was involved, criminals and innocents were arrested and tried. In the end, it was revealed that the document in question could be purchased from Bell itself for $20 and was in no way dangerous to the 911 system. An entire new organization had been created to fight for freedom online. Police and hackers had both come to a new understanding of their counterpart in the cat and mouse game of cybercrime.
The book is part historical and part investigational reporting. It covers the development of hacking culture and the internet over the past 100 years. It then dives into the hacker culture of the late 80s, which was often about hacking complex system just to get a reputation as someone capable of such. The book then pivots 180 degrees to talk about police and cybercrime. It starts with a history of the secret service, who for historical reasons are the ones to investigate many hacking activities. Both groups, their motivations and their habits, are explored in the specific case of the 911 document and the legal actions taken after it was found to be stolen.
I was expecting to learn something about hackers from this book, and instead I learned something about police and policing. I came away from the book disliking computer criminals more, even in spite of also liking hacker-kids more. The book manages to draw a careful distinction between those who explore for fun and reputation versus those who exploit for personal profit.
I also, surprisingly, came away from the book with much more appreciation for the police. The book doesn’t really let the police off the hook. They made some hilarious investigative mistakes in the original hacker crackdown of the 90s, and really overly punished some youthfully exuberant kids. That said, the book did change my mind about the importance of investigating cyber-crime, as well as its prevalence back in the early 90s.
Cyber crime in 2022 is, if not well understood, at least taken seriously by everyone. It’s common to hear stories about espionage, sabotage, and extortion. As an electrical engineer and software developer, I’ve been involved in truly extensive engineering efforts to make hardware harder to hack. Whenever I do, there’s always a small part of me wondering what the hardened system would look like to 16 year old me. I’ll often wear a black hat while designing the security for my hardware, trying to think about how 16 year old me (and even worse characters) would try to break in.
I’ll also be wondering about how 16 year old me would see the system from an exploratory perspective. There’s a tendency to harden everything these days, in a way that makes exploring systems that you own very difficult. I have fond memories of building computers, bricking them, and building new ones as a kid. Feeling the first wonder of programming when I saw my classmate’s calculator playing snake. Writing terrible encryption software to mess with my middle school friends. It seems like modern devices are more sleek than this, their experience more managed, and thus less inspiring to young hackers. Part of me worries they’re missing out, but I’m sure today’s version of 16 year old me is out hacking up some other system. I’m kind of excited for my kids to hit that age so I can see what the new hotness is then.
In spite of my current work trying to secure systems, there’s a fondness in my heart for people that want to learn how to break them. The discovery motive is noble, and it’s also a real thing that drives a lot of people like me. I’m not so fond of the people who just want to break them for profit.
This was where the Hacker Crackdown taught me something new. Or at least made me think seriously about something I’d been doing for years. Actually, some hackers are committing crimes and making the world worse for people! Those security systems I’d spent months designing into my hardware were actually there to prevent real people from doing real bad things, not just to torment people like my younger self! When police try to crack down on that, it’s possible that they’re actually providing a public service.
I feel almost like I’m betraying my younger self by writing that, given how obviously the original Hacker Crackdown of 1990 mis-stepped. What Sterling’s book did was help me see why people thought the crackdown was necessary in the first place, and why they used the methods that they used.
One of the more surprising passages in the book is a discussion of warrantless asset seizure. Sterling describes how a large part of police-work is not about arresting people, but managing neighborhood problem areas. For example, police may do a raid on a drug dealer’s house and take all of their money, drugs, and paraphernalia. This (sometimes) isn’t a part of trying to prosecute the dealer. Instead, it can be about making the dealer’s life harder so that they choose to change professions.
There are two ways to view this kind of thing. First, and the only way that I thought about this issue before reading this book, is that the police are being corrupt. They are taking property that isn’t theirs, for reasons that don’t involve putting anyone in jail, and without plans to return the property later. Obviously this is just police stealing stuff they want and using their status as officers to get away with it.
The other way of viewing this issue is as a form of harm reduction. Getting prosecuted sucks. Even if you don’t go to jail, you still have to show up in court, possibly pay bail, and deal with a huge hassle. If you’re convicted and go to jail, that can ruin the rest of your life. After being in jail it can be hard to get jobs, to get apartments, to vote, to do a lot of things we take for granted. Obviously asset seizure is a way for police to intervene in illegal situations without having to ruin someone’s life; a way for them to give people a few chances before they bring the criminals into the justice-system and grind them up.
Which of these things is happening probably depends a lot on the specifics of each situation, both the potential criminal and the police. What makes the seizure of computers in the hacker-crackdown so egregious is that many of the machines taken were used by law-abiding citizens to do normal work. It was in no way, shape, or form a way for the police to pressure criminals back onto the straight-and-narrow outside of prosecution.
But look at it from the police’s view, way back in 1990. Almost nobody uses computers, there’s good evidence that stolen property was on the computers, who would even think that the computers are being used for lawful business. It’s not like needles and pipes in a drug-den are used for lawful business.
This is the biggest mindset shift for me after reading this book. I no longer see the police in the hacker-crackdown situation as being corrupt. I see them as being uninformed and ignorant.
But this also brings up a question about asset seizure in the current day. We often hear stories now about police seizing tens of thousands of dollars from random people, without pressing charges. If you assume the police aren’t corrupt, then maybe this was seized from a drug dealer and the police have successfully pressured someone into a moral life without putting anyone in prison: a net win. If you think the police are corrupt, then maybe this was seized from a law abiding mom just trying to make ends meet: an obscene miscarriage of justice.
Public perception plays into the effectiveness of asset seizure without prosecution. If most people think asset seizure is done for corrupt reasons, then it’s going to be much less effective at stopping crimes. It’s also going to make police look bad and make it harder for them to do their jobs, even if in any given case they are doing it only with the best of intentions.
This is why it’s so important for police to be highly professional and honorable. Tools for keeping the peace can just stop working if people don’t trust the wielders. I’m reminded of Matt Yglesias‘s point that fixing America’s problems with police isn’t about just reducing the number of officers. We need better police. Police that get held accountable when they seize assets corruptly. Police that are worthy of the trust that their profession needs to function. The hacker crackdown of the 90s was just another crack in the professionalism and capabilities that police need.
My ideal is that kids (and adults!) can explore and figure out how stuff works and sometimes accidently break stuff without it ruining their lives. My ideal is also that people who are trying to take advantage of others for their own gain aren’t able to do so. I’ve gained a new understanding that people really are actually trying to do bad stuff using the same skills that explorers develop (I always knew this, but it seems more real now). Sometimes it makes sense to have police investigate and punish evildoers, but also police are often behind the curve on new technologies. I don’t have any major changes in policies I support after reading this book, but I do think I have a better sense for the nuance in certain technical and criminal issues.
This started as a book review, then turned into random musings on education. Be warned that it’s less well-researched than average.
I first read Scott Alexander’s review of Raise a Genius four years ago, before my wife was pregnant. It was interesting, but mostly from a theoretical perspective. We didn’t have kids yet, and I knew I had at least five years before I had to worry about school for prospective kids. I read the book review and moved on with my life.
Now I have two kids. Now my feeds are all full of peopletalkingabouthowterribleschool is. Now I’m worried about my kids being left unprepared by failing schools, and there are things I think I could do about it.
I went back to Scott’s review looking for actionable information. What can I be doing with my two year olds now to prepare them? What can I do when they’re in school to keep them happy and learning well?
Scott opens his review by saying that Lazslo Polgar, author of Raise A Genius and parent to three chess masters, doesn’t have any secrets. As Scott phrases it, Polgar “starts young (around the time the child is three), focuses near-obsessively on a single subject, and never stops.” The rest of the book, according to Scott, is just Polgar whining about the government, esperanto, and the nature of genius.
Scott then goes on to give some very long excerpts from the book, which he summarizes as “excellent-but-not-that-different-from-common-sense educational advice”. Those quotes don’t strike me as being common sense educational advice. It’s certainly not advice that I ever heard about how to raise my own kids, or saw in practice when I was in public schools.
This is especially true when Polgar talks about things like peer groups (age-match is less important than ability-match) or grades (there’s no need for them). I began to distrust Scott’s summary, and downloaded a copy of Raise a Genius to go through myself. It was a lot more useful than Scott’s review indicated.
How happy are genius kids
One thing Scott gets right about the book is how much time Polgar spends defending “Genius Education”. Most of his time teaching his daughters was also spent trying to convince his government to let him do it. Hungary (at least when he was teaching his daughters) had much different rules about home-schooling than the US does. While much of the text is very specific to Hungarian politics, it’s also useful for understanding the impacts of his method.
To be honest, I was very reassured by his descriptions of how well-adjusted his kids were. Home schooling genius children has a bit of a sketchy history. Norbert Wiener, for example, was tutored by his father and became an amazing mathematician at a very young age. He also was intensely socially awkward for his entire life, and infamously incapable of handling day-to-day tasks. John Stuart Mill is another towering figure raised from birth to be a genius. He fell into a deep depression and almost killed himself when he was twenty. Both these people did great things, but I do wonder if they had good lives.
I want my kids to be capable and successful, but maybe not at the expense of their mental health and happiness. Maybe I would accept my kids struggling a bit more with school, or earning a bit less money throughout their life, if it meant they had an easier time making friends and feeling good about themselves.
Polgar does a pretty good job arguing that you don’t have to trade off between genius and happiness. He claims that raising kids the way that he did doesn’t hurt them, either emotionally or socially. It obviously leads to them being very capable and skilled (at least in a few areas). From what I’ve seen, his daughters (now adults) agree that they weren’t hurt by their education.
When you look at what Polgar did, it’s pretty different than what was done during Norbert Wiener’s childhood. Polgar emphasizes games and holding a child’s interest. He says that chewing a kid out is detrimental. Wiener’s entire childhood was being quizzed until he failed, then chewed out for it. John Stuart Mill’s childhood seems pretty regimented, and it seems he thought that he was denied a normal childhood. His autobiography does talk a lot about things he enjoyed in his childhood, though mentions that amusements were carefully regulated.
For Polgar, the right way to teach children is to make the lessons playful. Keep it rigorous, but also keep finding ways to engage kids in the lesson. Make them fun or useful to the kid. And usefulness is key. He talks a lot about how language learning in particular can instill a love of learning, because kids can see it’s useful as soon as they can talk to new people in a new language. kids want to do useful things, so make education useful and they’ll want to do it.
Genius education also focuses on meeting the kid where they’re at. It’s no use to teach a lesson that’s too hard or too easy. You need to teach each lesson at exactly the right level for the kid’s current expertise. That definitely puts it out of reach of modern public schools, and requires either very good software or a very high teacher/student ratio.
Polgar stays pretty far away from recommending that everyone use his system. He wrote his book to say “it’s fine to do it this way if you want” not “this is the best way to raise kids”. That’s a big difference, and it’s one that he emphasizes a few times. It’s a difference that makes me trust him quite a bit more.
Social concerns
It’s pretty common among people advocating for genius education (at least on the internet) to also advocate for genius rule. You see this a lot when people want politicians (or worse, voters) to be required to pass science tests. You even see this when people advocate cloning one million John Von Neumanns to solve all our problems (yes really).
I don’t like this idea.
It’s not that I don’t want my political leaders to be competent and informed. I really really do want that. The tragedy of covid has been a stark illustration of what happens when your politicians aren’t competent enough.
It’s also not that I think having competent people in a society doesn’t improve that society. Geniuses, researchers, and inventors help improve the world in profound ways. I do want my society to be full of smart, well educated, competent people. I do think that would make life better for everyone in my society, even ones who might not be as competent.
The problem I have is that ways to explicitly put geniuses in power are easily gamed. I don’t like explicit plans for formal genius-based leadership for the same reason I don’t like enlightened monarchy. Sure, if your leader is highly competent, smart, and selfless then your country will flourish. But your next leader may not be as smart (or worse, as selfless). The one after that maybe less. History has taught this lesson over and over.
Similarly, the strong forms of eugenics from the early 1900s were a travesty, and I loathe the thinking that led to them.
Polgar doesn’t want to install geniuses as the leaders of the world. In his own words, he wants “to democratize the notion of genius”. This really comes through in his idea of who could be a genius.
Polgar thinks that, at birth, almost every kid has the capacity to be a genius. Through poor nutrition and bad parenting, the fraction of kids with “genius potential” degrades pretty quickly. Later, schools do a pretty good job of squashing genius potential in the rest of the kids.
Polgar thinks most kids are born geniuses, and we just beat it out of them.
If you really believe this, the current way we raise kids is a disaster. It also means (and I think Polgar believes) that we don’t need special programs to insitute genius-leadership. We just need to improve child rearing and education and the rest will take care of itself. I lean a bit more on the nature end of the nature/nurture debate than Polgar does, but the ethic behind his education system seems good to me.
This is important because I want to raise my kids to be competent, but also to be a positive influence in the world. To be moral and just. I think a part of doing that is teaching kids in a way that encourages moral thinking, which is something Polgar has put a lot of thought into.
What to teach
One thing that Scott Alexander really got right in his review was how important Polgar thinks it is to focus on one topic. Raise a Genius emphasizes, over and over, how important it is to focus on one thing at a time. In practice, Polgar does this in two different ways.
The most visible way Polgar focuses on one topic is by choosing to make his daughters into chess masters. He basically says you can choose any topic, but you have to focus on that. Then he allocates 4 hours a day, every day, to studying that one topic. He explicitly encourages parents to choose the expertise their children are going to have.
The second, less visible, way that Polgar emphasizes focus on one thing at a time is how he starts his kids on new topics (like a new language). New topics should be introduced intensively. Polgar says that new topics should be done for 3 hours a day, and time should be taken away from the main specialist study (chess in his case) for those hours.
This is the exact opposite of what public schools in America do. When kids are going to learn a new subject, they spend around an hour a day on it. It’s slotted in with all the other things they’re learning, with no special emphasis.
My take is that Polgar thinks incrementalism is good for improving knowledge of a subject you already know a bit about, but sucks for learning a new subject. This may explain why so many kids come out of public school not being able to do basic math. The one-hour-per-day schedule never gives them the push to get over the initial difficulty.
Based on my own personal experience, I one hundred percent believe the second form of focus Polgar likes is worthwhile. In the future, when my kids are starting to learn something new, I’m going to try and have them focus on one thing at a time and put a bunch of effort into that one thing.
One the other hand, I’m a bit less sold on Polgar’s primary form of focus. Choosing the expertise that your child will have growing up just feels a bit skeevy to me. This is probably a pretty common reaction (especially in modern western cultures), so Polgar spends some time on justifying the idea.
Polgar sees two ways of smoothing a kid’s path to a good adulthood:
let the kids sample everything, and decide for themselves very near to adulthood what to do
decide early (even in the kid’s infancy) what the kid will specialize in
Seeing Polgar break it down like this was enlightening for me. My experience as a kid, and looking at child-rearing advice now, is entirely about letting kids sample everything. The common advice to follow your passion takes for granted that this is what you’ve done, so that you’ve sampled enough to know what your passion is.
Polgar’s method is completely centered around the early-specialization option. He decided his kids would specialize in chess, so they did. This is also pretty much what Wiener’s and Mill’s parents did. Their parents both had specific ideas about how their kids should contribute to humanity (math in Wiener’s case and utilitarianism in Mill’s case).
I am an engineer. My dad was an engineer. The uncle that was most involved in my childhood was also an engineer. I farted around a lot in college, but it seems like a foregone conclusion that I would always end up in some form of engineering. That’s what I saw was valued when I was a kid, and I also had a lot of engineering related books, games, and tools from my family. My parents may not have intentionally chosen my profession for me, but they sure smoothed the way towards the path I’m on now.
My best friend is a musician. His dad is also a musician, and his dad talks a lot about his time with the Beetles and other famous musicians in the 60s. I think my friend’s dad would have been fine if my friend hadn’t ended up being a musician too, but it sure is a good way for them to connect with each other now that they’re both adults.
My brother-in-law is an engineer. My brother-in-law’s dad is an engineer. My brother-in-law’s grandad was an engineer.
One of my uncles has a construction business, and several of his kids work there. They are explicitly following in his footsteps.
These things happen. Family helps family, and if you’re in a given career then one of the best ways you know how to help a younger family member is telling them what they need to succeed in your career path.
I’m not sure how much I can reject choosing my kids profession. I very much want them to appreciate and respect the work that I do. I want them to know how to do it, because I think the work I do is cool and useful. I would be fine with them choosing another job/career/passion, but some part of me would find it easier to connect with them if they went into the same specialization.
Polgar’s method just formalizes this. Instead of incidentally inspiring my kids to be engineers, Polgar would have me explicitly choose it and prepare them for it. They’d be better engineers if I followed Polgar’s advice.
Family and Children
The idea of choosing your child’s expertise when they’re only three years old is strange to WEIRD sensibilities. That idea is just one part of a larger question of how a family should function. Polgar has a section specifically on family, and asks questions that I would never have thought to ask.
The two main questions of how a family relates that stuck with me were on education and on marriage. Education is the whole rest of his book, but his thoughts on marriage were pretty surprising to me.
Polgar starts with this question: how much should parents be able to influence who their kids marries? This question ties into how much parents should have a say in what their kids do for a job, where they live as adults, etc. I understand that there’s a lot of variety in how that question is answered across cultures, but I have to admit that before reading Raise a Genius I thought America’s answer to that question was obviously best.
When I got married, my only living parent had no say in it. It didn’t even occur to me to ask my mom if she was ok with it, or if she thought it was a good idea. If I had asked her, I don’t think she would have felt comfortable giving me an honest answer.
In hindsight, not having any input from my mom about who I was marrying feels… alienated? Like I wasn’t actually connected to my birth-family, and they didn’t care about who I was marrying?
It’s interesting for me to have these thoughts now that I have kids of my own. When I was younger, it was obvious that I didn’t want to have my parents making my life decisions for me. Now that I’m a parent, it seems obvious that I could make my kids life easier by putting my finger on the scale for certain decisions my kids may face.
It’s honestly funny to me how much my internal feeling about the issue changed when I was the parent instead of the kid. I remain uncertain where exactly I’ll fall in the guidance vs total freedom tradeoff, but after reading Raise a Genius I’m much less certain about the total freedom model I grew up with.
Schools and Children
If my culture is leaning away from making any explicit decisions for kids, the schools available to us are doing the opposite.
Public schooling in America actually does make most of the decisions for kids. Until high school, I had to take exactly the classes that I was assigned. Even in high school, I had to choose from among nearly identical english classes, nearly identical math classes, and so on. I couldn’t just not take english (not that I’d wanted to skip it in particular).
The freerange kids movement is pushing against this by encouraging parents and educators to let kids figure things out on their own. Years ago, before reading Raise a Genius, I was very sympathetic to this idea. Then Polgar had me thinking that we need to carefully guide our kids. Then later I read Hunt, Gather, Parent and became convinced that I should let my kids be more independent (though being careful not to let them be isolated).
The huge variety of parenting advice and education advice makes me think that individual techniques are probably less important than the underlying philosophy of connecting to kids and giving them agency. Even Polgar sees the importance of this when he describes how important it is for kids to see the use in what they’re learning.
This is probably one of the main worries I have about our education system in America: that it denies any agency to kids. It removes any purpose from what they’re learning aside from grades.
I really like math. I think it’s an intriguing subject. I used to excitedly agree with my teachers that “when are we ever going to use this?” was a terrible question because learning was its own reward. Now I don’t. Conveying to kids that the thing they’re learning is useful is maybe the most important part of teaching. But intriguing things are useful in their own right. Young kids know this instinctively (at least mine do, as they’re happy to get engrossed in things and spend hours on them).
If a kid asks a teacher how something is useful after the teacher has taught it, I now think that teacher has already failed in their job.
But really, what to teach?
My kids are almost three, the same age Polgar’s daughters were when he started intensive training for them. What would he say I should be teaching them?
Here’s where Scott’s original review of Raise a Genius gets it right. Polgar pretty much just teaches the same topics that our schools teach here in America. He teaches them differently (with the focus, playfulness, and usefulness as discussed above), but the topics are the same with only a few surprises.
Polgar requires the already mentioned four hours of specialist study, and then spends time on social studies, science, computing, psychology, gym, etc. It seems he doesn’t do all of these every day. For example, some days he’ll do social studies, some days science.
One thing Polgar does every day is humor lessons. He mentions that he takes 20 minutes out of every hour of humor lessons for joke telling. I would have loved more insight into this one.
Polgar also sees physical education as being critical, but he doesn’t emphasize it as much as he emphasizes the other topics. Instead of “teaching” it, he just says that kids can do any “freely chosen” activity outside of school for an hour. Given the modern tendency for everyone (kids and parents alike) to sit around on computers or phones all day, I think gym (or at least recess) is probably one thing I’d want to explicitly make time for inside of school.
Polgar doesn’t say anything about this list of topics changing with age, so my guess is that the level of the topic is adjusted to the kid. No matter the age, he’ll still advise teaching computing, social studies, etc. No matter the age, he’ll still hold humor lessons.
How will I educate my kids?
For Polgar, the education of his daughters was his life’s work. They were his project, his day-job and his passion. Educating his kids, to prove that his form of education worked and that girls could be good at chess, was his mission in life.
I love my kids, but they are not my life’s mission. I’m not going to quit my job next year to homeschool them 9 hours a day. I want to build robots, and giving up my life’s work of awesome robots would also not be a fair burden to place on them. I want to demonstrate to my kids that they can dream big and work hard and go far, and then give them the tools to do that. Dropping out of my dreams to raise them won’t do that.
So I won’t be using Polgar’s genius education. I basically knew this going into the book. I wasn’t looking to follow Polgar’s Raise a Genius like a manual, I was looking for tools I can fit into my own family life.
There are a few concrete things that I’ve decided to do based on the book. These are:
play more games with my kids
humor lessons. This one seems awesome for them and for me.
when they’re starting a new subject, spend time with them working on it and emphasizing it in the evenings and on weekends
enable my kids to spend time with intellectual peers, even if they’re of different ages
find ways for my kids to be the experts in things, and to demonstrate their knowledge
The early vs late specialization question is also on my mind. I do plan to teach my kids a lot of technical concepts, just because I think it’ll be awesome and fun. My wife will likely be teaching them a lot of literary concepts for the same reason. Given the world we live in, I feel unsuited to choosing a life path for my kids that they’d be taking up 18 years from now. The world is changing quickly, and I’m not sure I could pick something that would be a safe enough bet. I’d rather give them lots of tools and let them dive deeper when they know what they need later.
Other things that I could do for them are pretty dependent on what their school life ends up being. Schooling is a hard problem, and I’m not sure we as a country are getting better at it. It seems like we’re learning a lot of ways that we can improve education, but that they rarely transfer well or they only work for certain kids. It also seems like a lot depends on the teacher, and the teaching profession in America seems totally fucked.
If my kids go to a school that works for them and they do well, then maybe the above list is all I’ll keep from the book. If they go to a terrible school that makes them miserable, then maybe we will try to move. If they’re somewhere in the middle, then we’ll try to deal with it.
Mitigations for a bad school
I expect that my biggest struggle when my kids go off to school will be to continue to trust them. From everything I’ve read and seen, they will know if they’re learning or not. I just need to be able to listen to them. Right now, I want to teach them whatever they want to learn, whenever they’re ready to learn it. If a school isn’t doing that, I want to change things.
Some people actively avoid teaching their kids, because they’re worried the kids will be bored in school. Gunnar Zarncke talked about getting his kids interested in math, but then avoiding teaching them certain concepts. That’s just one example of this trend. But if everyone is avoiding teaching things until kids get to school, that seems like it would slowly bring down the bar for all kids.
A recent Psychology Today article talks about how teaching kids at a pre-set schedule (as opposed to when the kids are ready) can lead to learning disabilities. By forcing kids to learn things before they’re ready, school can instill anxiety that then actively prevents kids from learning later on.
Polgar taught his kids exactly what they were ready for. He knew his end goals for his subjects, but tailored the individual lessons to the kids. He talks about making up games to keep things fun, and tuning the games to be at exactly the growing edge of the kids knowledge.
It almost seems that schools get this exactly backwards. They have a rigid schedule of when to teach any specific lesson, but loose and unclear ideas of what they want kids to be capable of when they graduate.
In high teacher/student ratio education, level setting for individual lessons can happen naturally. That’s hard to do in a modern public school. When one teacher has 30 kids to teach, they’re not going to be able to tune the class to everyone’s level. That is a fundamental limitation of the modern schooling model.
I’m thinking that I should be talking to my kids regularly about how they’re liking school. About whether it’s going too slow or too fast. Then trust them about those things.
If they think it’s going to fast, I can take time on the evenings and weekends to help them. I can find a tutor to help out if necessary. Get them caught up to the point that they can follow class again. This seems important to catch early, so that my kids don’t get a complex about it.
If my kids report that things are going too slow for them, the answer might actually be the same. Certainly in the short term extra tutoring and weekend projects will probably help them to stay invested in learning. Longer term, it may make sense to seek a different class or school.
Resiliency in and out of schools
There’s a common idea that school shapes your kid. It does everything for them: reading, writing, arithmetic. Also critical thinking, morals, and political thought. What if we should all expect less from schools?
What if there are things that are better taught at home, that will actually make school more useful too?
Kids who have agency, and are connected to friends and family, will suffer less from bad schools and prosper more from good schools. Those two keys, agency and connection, aren’t going to form in the school. That’s the main thing that I want to focus on as a parent.
Those keys are also crucial to what Polgar did for his kids. He gave them agency by showing them that they learned useful things. He showed them it was possible to know more than their parents; that the kids could be the experts. He also gave them community and connection. He brought his kids to groups of intellectual peers, in chess and in language learning. I wonder how loadbearing these few things were for Polgar. Perhaps moreso than the individual lessons or what he chose to teach them when.
This is what I’m trying to give my kids now, before they even start school. The understanding that learning leads to knowing, that knowledge is power. Also the ability to connect with people of various ages, backgrounds, and interests. Maybe with this, they’ll be able to enjoy school.
With thanks to @scottleibrand for his regular posts on covid studies.
My wife and I are both fully vaccinated now. If we didn’t have kids, we’d be planning our amazing summer of travel. Seeing everyone that we’ve missed, going to restaurants, and generally being social.
But we have kids. Two year olds. They won’t be getting a vaccine for a while yet. What do we do to keep them safe?
Covid in Kids
My naive understanding is that covid is not very dangerous for kids. How true is that, actually?
There are two parts to this question:
How likely are kids to get covid?
How bad will covid be for them if they get it?
Will they catch it?
The good news is that kids age 0-4 are less likely to get covid than adults. That age group is 6% of the population but only 2% of positive covid tests. Compare that with infected people in my age group, which is almost exactly the same as our prevalence in the general population.
On its own, this doesn’t necessarily mean children are less likely to get covid from a given exposure. It could be that they’re just taking fewer covid tests. It could also be that they are exposed to covid less often than adults.
That said, a meta-analysis published last September finds that those younger than 20 are only 44% as likely to be infected as those older than 20. This trend is even greater the younger the child is. The meta-analysis was on studies of secondary infections, meaning infections of housemates after someone in the house got infected from an outside source. The secondary infection rate is apparently considered a pretty good measure of the person-to-person spread of the disease.
But will they catch it from vaccinated people?
Kids may be half as likely to even catch covid as adults, but what about catching it (at all) from vaccinated caregivers. This is really what I’m interested in, as we’ll likely choose babysitters and events based on how vaccinated the adults are.
When the vaccines were first coming out, there was a lot of concern that they’d reduce symptoms but not infectiousness. I’m vaccinated now, but could I still technically “catch” covid and infect my kids without knowing it? Could a babysitter?
Back in April, the CDC talked about a study on around 4000 first responders who got vaccinated. These folks got PCR tests every week, regardless of their symptoms. This let the researchers estimate how well the vaccines block infection, as opposed to just reducing the symptoms once someone is infected. There was a factor of 35x reduction in infections between unvaccinated and vaccinated people. In particular, the vaccine effectiveness (for fully vaccinated folks) was 90% in preventing infection (not just symptoms).
This means that I personally could take more risks without worrying so much about bringing the virus back to my kids. My office (like most in my state) no longer requires masks for fully vaccinated employees. I’ve still been wearing one since my kids aren’t vaccinated, but it seems like I’m not decreasing my kids’ risk much by doing that.
Putting numbers on it
These two pieces of information make me optimistic, but it’s hard to figure out how to make decisions based on that. Vaccinated baby sitters are a pretty different risk profile than a group day-care (where kids with unvaccinated parents may be common).
I used the microCOVID project to estimate a few different situations that parents may be interested in. I used my local area, so you may want to recalculate these numbers for your area. The risk budget recommended by microCOVID is 200 microCOVIDs per week, which is a 1% chance of getting covid per year. Given children’s smaller likelihood of contracting covid in the first place, I divided all the microCOVID values by 2.
While the microCOVID calculator is designed for adults, it’s pretty easy to use for toddler interactions. I just assume that the kids are going to be running around grabbing each other, wiping their fluids on each other, and generally being super gross adorable.
As of May 2021, the microCOVID project can’t handle assumptions about hanging out with other people who are vaccinated. To get around this, I assumed that the vaccinated people were in the “200 microCOVID budget” category.
having a vaccinated baby-sitter over for 4 hours: 35 microCOVIDs
having a 4 hour play-date with another kid and their vaccinated parents: 100 microCOVIDs
going to daycare with 20 other kids for 40hrs/wk: 1000 microCOVIDs (52000 microCOVIDs/year)
having a vaccinated nanny watch your kid for 40hrs/wk: 100 microCOVIDs (5200 microCOVIDs/year)
In other words, sending your kid to daycare would provide a 5% risk of them catching covid in the next year (assuming vaccine use doesn’t increase, lots of unvaccinated parents, etc.). The real risk is probably already lower than this.
If you get a vaccinated nanny for 40 hours a week, that would be a yearly chance of covid of around 0.5%. That’s assuming one kid, but we have two toddlers. If one gets it, the other will definitely get it as well. So our chance would likely be more like 1% per year (again assuming no change in the prevalence). Likely this probability will decrease as vaccination rates among adults go up.
How bad would it be?
So let’s say you send your kid to daycare and they catch covid? How bad will it be for them?
The good news is that covid is usually not very bad for kids (as people have been saying forever). That doesn’t mean there’s no risk. There have been a couple hundred child deaths from covid over the past year. That’s tragic, but it’s also not very likely to happen to a given (otherwise-healthy) child.
This paper on outcomes from the first peak in England back in the early part of 2020 gives us some better details. They found a case-fatality rate among children under 16 to be 0.3%. That’s the chance of death at the very beginning of the pandemic, given that the kid definitely has covid. I’d bet that number has gone down significantly since this paper was published, as people have learned more about how to treat the disease.
Kids aren’t likely to die, but what about other symptoms? A recent paper by Castagnoli et al. shows some epidemiological statistics for the early stage of the pandemic. Most kids were asymptomatic or had only mild respiratory symptoms (like a cough). Honestly, it doesn’t sound as bad as when my kids got the normal flu a year ago (which was horrible! Get a fucking flu shot!).
Comparisons to other daily risks
It’s easy to look at covid risk numbers and get freaked out. I find it helps to compare against risks that we take every day. For example, what’s the risk of travelling cross country to gramma’s house? Long road trips expose your kids to risk of car accidents, which are actually a pretty common cause of death in America. We decide that it’s totally worth driving across the country so our kids can see gramma. How does that stack up against covid risk?
Wikipedia helpfully summarizes the literature on dying from travel as 1 micromort per 250 miles. If we’re driving 500 miles to see gramma, that’s a risk of about 4 micromorts for the round trip.
(For those of you not familiar with micromorts, it’s a one-in-a-million chance of death. So taking our kids to grammas is a 1 in 200 thousand chance of death. Do that 20 times over the course of their childhood and it’s more like 1 in 10 thousand.
Let’s convert the microCOVID risks above to micromorts (chance of death) using the 0.3% case fatality rate number. This is likely an overestimate, but I think it’ll get us in the ballpark. This ignores the suffering that the kids face if they get sick and recover, but I think it still gives a pretty useful comparison point.
having a vaccinated baby-sitter over for 4 hours: 0.1 micromorts
having a 4 hour play-date with another kid and their vaccinated parents: 0.3 micromorts
going to daycare with 20 other kids for 40hrs in one week: 3 micromorts (156 micromorts/year)
having a vaccinated nanny for 40 hours a week: 0.3 micromorts (15.6 micromorts/year)
These all seem pretty safe, if all you’re worried about is your kids dying. Every one of them is safer than a cross-country road trip, though the yearly risks for nannying are slightly higher than a single road trip and the yearly risk for daycare is much higher. I personally find all of these risks worth it for the benefits that the activities would bring to my kids lives.
Long Covid
The thing that I really worry about is long-covid. People that had covid, maybe even a very minor case, who then end up with very long lasting health effects.
That epidemiological statistics paper by Castagnoli that showed most kids had only minor respiratory symptoms? It also showed that the kids had “[b]ronchial thickening and ground-glass opacities” in their x-rays. That sounds really bad. Is it going to crop up and harm them later on in life?
To say aloud a thought that seems worth saying aloud: My inner Science Genre-Savvy guesser, has a suspicion that long Covid / post-Covid syndrome, might turn out to be *real but not special*. By which I mean that if our science-larping establishment manages to…
Now it may be that long-covid is just one source of various unexplained chronic illnesses that people can get. I would jump through a lot of hoops to prevent my kids from getting something like Chronic Fatigue Syndrome. If the risk of my kids getting a chronic illness from a mild covid infection were high enough, I would absolutely be willing to isolate our household for several more years until they become eligible for the vaccine.
The risk of long-covid to my kids is a difficult thing to get a handle on. We’re still learning what long-covid even is and how it impacts people, so I’m just going to summarize some of the more informative papers I’ve seen on it.
The most worrying long-covid evidence I’ve seen so far is this Nature paper studying the effects of covid on people six months after diagnosis. It compares people who used Veteran’s Affairs medical systems, and contrasts long term results of those who did get covid from those who did not. They find that people who get covid had higher usage of pain killers, higher usage of medical therapies in general, and higher incidence of a variety of medical issues (mostly centered around lung problems). This paper also compares 6-month covid complications with 6-month flu complications, and finds the longer-term covid complications to be worse than those for the flu.
Summary, 6 months follow up: -60% higher risk of death -3% of all patients have lung issues or abnormal blood work (enough to see doctor), >1% have a variety of issues -hospital/ICU increases risk++
A 60% higher risk of death, 3% of post-covid cases have lung issues or abnormal blood work, and >1% have some other issues. I’m a little unclear on the difference between hazard ratios (that the paper used) and relative risk, but this seems like a reasonable read to me.
Another study from the UW found that 30% of people who had covid self-reported persistent symptoms (mostly fatigue). That study was pretty small, and only looked at survey data. It does seem consistent with post-viral syndrome, where people who catch a virus can remain fatigued for years afterwards.
A more recent survey in Nature found that 2.3% of their covid-positive population reported symptoms lasting more than 12 weeks. That seems to track pretty well with the results of the Veterans Affairs paper discussed above. This survey also provides evidence that the older you are, the more likely you are to get long-covid (a positive sign for those thinking about the risk to their young children). Other risks that contributed to longer covid symptoms were severe symptoms requiring hospitalization (unlikely in children), and asthma.
A lot of the symptoms described in these papers seem more mild than those in the long-covid horror stories I’ve heard. I’m also heartened by the fact that most people who have longer term symptoms do seem to get better.
There also seems to be some small evidence that people who get long-covid recover (at least a bit) after getting the vaccine.
Long-covid risks for kids
Based on the above studies, it seems like there’s an upper bound of 2.3% for the probability that my kids have covid symptoms more than 12 weeks after getting infected with covid. Given that younger people seem to have fewer issues, I’d be willing to bet that the real probability is even lower. Let’s use 2.3% to get some numbers on risks and see what happens.
Instead of inventing some new unit like microLONGCOVID or something, I’m just going to use % chance of getting long-covid. In theory you could calculate DALYs if you really wanted to, but I’m not sure there’s enough data on the impact of long-covid to do that effectively.
having a vaccinated baby-sitter over for 4 hours: <0.0001%
having a 4 hour play-date with another kid and their vaccinated parents: <0.00025%
going to daycare with 20 other kids for 40hrs/wk: <0.0025% (<0.12%/year)
having a vaccinated nanny watch your kid for 40hrs/wk: <0.00025% (<0.012%/year)
Decisions
I want to emphasize that the estimates I gave above are based on some very hand-wavey assumptions. I took case fatality rates from early in the pandemic, and they’ve likely improved since then. I took long-covid incidence from the general population, and evidence is that things are safer for kids. I assumed vaccinated people now had the same risk of getting covid as people on 200 microCOVID budgets at the height of the pandemic (probably a big overestimate).
I’m not using the numbers above to get a real true risk. I’m using them to get an order of magnitude estimate that I can compare against similar risks. From what I’m seeing, there’s one main takeaway for me personally: I want to hire a babysitter and go out again!
Kernighan’s history of Unix is a first person account of how the operating system came to be, and how it came to be so ubiquitous. It’s also a great overview of Bell Labs culture, and why it was so productive. The book is interesting, readable, and informative. A fairly quick read that’s still full of useful knowledge.
Each chapter is a part of the Unix development history, followed by a short biography of someone involved. This worked really well for me. The history part of the chapter connected what I knew about the OS with people who worked on it and the design decisions they struggled with. The biography section of the chapter would then go into more detail about one of the people involved in those design decisions, often showing some interesting background about why they would have had the thoughts they did.
There are a lot of anecdotes about how and why things were built the way they were. Some of these come off as simple reminiscences (and the book is part memoir). Other anecdotes really clarify the technical reasoning behind some of Unix’s features. I’m used to thinking of Unix through the lens of Linux, which is (currently) enormous and complicated. That’s pretty different than Unix during it’s development, when the source code could be printed in a single textbook alongside with line-by-line annotation. The book gave me the impression that Unix was created by some highly educated people that were just seeing what they could do, while also trying to make their own jobs easier. Each step of Unix’s creation was a small improvement over what someone was already doing, followed by a bit of cleaning up to make it all work nicely together.
A particular string of anecdotes really changed my understanding of the OS and it’s associated command line tools. When I use command line utilities like grep or sed or Make, it’s often in a cookbook format to accomplish a very constrained goal. I viewed them as tools that have specific configurations I can tweak, like I drill that I can change the torque on. That’s pretty distinct from how a lot of the Unix authors viewed things. They were very much working from the idea of languages. For Kernighan, sed and grep aren’t tools. They’re parsers for a general language. Make isn’t a configuration file, it’s a language that gets parsed. This is one reason that they were able to make so many powerful tools: they treated every problem like a translation problem, and wrote languages that would help. This change in mentality from a “tool” to a “language” feels large to me.
In addition to gaining insight into the decision process that drove Unix development, the book also spends a fair amount of time on the culture of Bell Labs. Bell Labs has a kind of mythic status, appearing in many history of technology books (including at least one that focuses on Bell Labs specifically). This was the best book I’ve read that described the organization of Bell Labs from the perspective of someone who was there.
Bell Labs Funded People
Bell Labs was a great example of the “fund people” method of research, as opposed to pretty much everything today. This idea, which is also discussed explicitly in the book, is that the modern scientific enterprise is too focused on giving money only to people with concrete problems they’re trying to solve. By only giving funding to short term concrete projects, our society is limiting the process of discovery and improvement.
The Bell Labs approach to funding research was:
step 1) hire people at the cutting edge of their field step 2) there is no step 2. If you’re doing something here, you’re doing it wrong.
Kernighan describes how he started working at Bell Labs, and was never given a project. He just kind of wandered around the halls talking to people until he found some interesting things to work on. Everybody at Bell Labs was like this. Nobody had an official project, they just did whatever they felt like and published or patented what made sense after the fact.
Some people sometimes had concrete projects. Apparently when Ken Thompson started at Bell Labs, he was asked to help write the Bell Labs component of Minix. Minix was an operating system project being run out of MIT that had very lofty goals and a very complicated design philosophy. Bell Labs eventually pulled out of the project for reasons that aren’t clearly explained in the book. Something something it wasn’t working out, it’s me not you.
After Thompson’s Minix project got scrapped, he just worked on whatever he felt like. He made an early space-explorer video game, he worked on a hard disk driver. Then he realized he was “three weeks from an operating system” if he reused some of the software he’d just written. So he made Unix. No grant process, no management review, no scheduling it around other obligations.
After that, several other people in Thompson’s department got interested in it. They all worked together to add tools and features and clean it up. None of them had to clear their work with management or get a new job-code put on their timecards. They just worked on the software.
That’s not to say that they were just playing around. Kernighan describes a lot of specific concrete problems that they were trying to solve. Things like document preparation, automated legal brief generation, and resource sharing. Everyone who worked on those problems did so in a way that was generalizable, so they were adding tools and techniques to Unix as they worked. Ken Thomson and Dennis Ritchie, the two main Unix inventors, were at the cutting edge of operating systems and language design, and they just kept trying new things and increasing what was possible.
There are a few specific takeaways here that are relevant to attempts to fix modern science funding.
Who do you fund?
Kernighan has several pages on how Bell Labs selected people to hire. It seems that Bell Labs would have certain engineers build relationships with specific universities. Kernighan himself worked with CMU for over a decade. These Bell engineers would visit their university several times a year to talk to professors and meet their grad students. Promising PhD candidates would go out and interview with Bell Labs engineers in a process that reminded me a lot of the Amazon and Google in-depth interviews I’ve done.
Teams
The secret of Bell Labs’ success, at least according to Kernighan, lies in the network effects of their office. They hired all of these people who were at the cutting edge of their field, and then put them all on a single campus. There were no remote workers.
This really kills my plan to get myself fully funded and then do math research in my underwear from home.
The Bell Labs network offered two things. The first was obviously access to solutions. If you didn’t know how to do something, corporate culture demanded that you go ask the leading expert two doors down from you. The culture was a “doors open” policy, and people would often drop whatever they were doing when someone came to them with questions.
The other benefit of the Bell Labs network is less obvious: it’s the problems. All of the people at the cutting edge of their fields were trying to cut a little farther. They were all trying to solve their fields problems. That meant that everyone had interesting problems to work on. This ended up driving a lot of Unix development. Someone would show up in Kernighan’s office needing help with some random thing, and Bell Labs would end up with another ground-breaking piece of software several months later.
It’s possible that the internet could replace some of this. Stack exchange and Quora, in particular, seem ripe for this kind of experts-helping-experts exchange. That said, I think the in-person nature of Bell Labs lowered barriers to collaboration.
There was also the knowledge that anyone you helped was an expert in their own field, which is not the case with online tools now. I think that would change the dynamic significantly.
Bringing back the greatness
If you wanted to bring back the greatness of Bell Labs in its heyday, you’d fund people instead of projects. But that slogan admits a reading that’s fairly isolationist. I don’t think you could match Bell Labs’ output by funding a bunch of individuals around the country. I don’t even think you could match it by funding a bunch of small teams around the country. I think you need the big research center energy. Fund people, but make them work near the other people you’re funding.
Jonathan Edwards has an interesting post about stagnation in software development. He argues that the Great Stagnation in economic development is also impacting software, and his evidence is that we’re still using a lot of the tools that are discussed in Kernighan’s history. Unix and C/C++ are still used all over the place. Edwards would like to see better operating systems, better languages, better filesystems, better everything. He argues we don’t have better everything because “we’ve lost the will to improve” since the internet lets software developers make easy money.
Is Edwards right? Will it be useless to Fund People, Not Projects because developers have lost their way? Edwards want another Unix project, another breakout operating system that fixes all of Unix’s mistakes. Kernighan doesn’t think it’ll happen.
The thing is, OS development now is not even in the same reference class as OS development when Unix was invented. In the 60s, all operating systems sucked. The people using them were all experts by necessity, and they were always ready to jump to the next big thing in case it was more usable. By contrast, operating systems now are adequate and used by the non-technical public. People may whine a lot about their OS, but they mostly do what people need them to do. Any newer/fancier OS would require people to learn a new skillset without offering them many benefits. No Unix replacement can spread the way that Unix did.
Unlike Edwards, Kernighan isn’t disheartened. Kernighan just thinks that the next major developments will be in different fields. And indeed, we have seen major improvements in things like machine learning over the past decades. Machine learning is in exactly the reference class of early Unix: it currently sucks, everyone who uses it is an expert, and they’re all ready to jump to the next thing in case it solves their problems better. ML is exactly the kind of place we’d expect to see another breakout hit like Unix, and it’s also an area that Edwards explicitly says doesn’t count.
Software developers are people. They enjoy solving problems, but want to solve problems that actually matter. I’m sure Edwards has a long list of improvements that can be made to any particular human programming software paradigm, but in our current place in the timeline those improvements have low expected value relative to other areas.
Software developers have not lost the will to improve. That will is still as strong as ever, but it’s pointed in a slightly different direction now. Edwards may not like that direction, but I think it’s a direction that will have a better impact on everyone. Now we just need to get all the bureaucracy out of the way, so the developers can actually push forward the state of the art.
I’ve been catching up on the Expanse lately, and just finished season 3. One of the earlier episodes in the season had the most sci-fi scene I’ve watched so far. It wasn’t the magic rocket engines or the arm-band cancer cures that impressed me. It was the retrieval of the Nauvoo.
The Nauvoo is an enormous ship debuted back in season 1. Intended as a generation ship, it’s incomplete when the intrepid heroes try to use it to batter an asteroid out of the way. The Nauvoo misses the asteroid, and ends up in a difficult to reach orbit without power or propellant.
So Drummer goes off to retrieve it. There’s a lot of in-space rendezvous in the Expanse, but this one really brings home how advanced their spaceflight hardware and software really is. To retrieve the Nauvoo, they use a hundred or so autonomous engines that fly out to it, clamp on, and then redirect the orbit.
Every part of this is impressive compared to what we can do now. Let’s break it down:
Coordination: There are dozens, maybe a hundred spacecraft all working autonomously and in concert to move the Nauvoo. We don’t know how to do this now (though it is one of NASA’s research focuses). Coordination is a hard problem because you have to let all the spacecraft communicate with each other, tell each other where they are, and decide which spacecraft is going to do what. Swarm robotics is hard. Imagine how hard normal robots are, and multiply that difficulty by the number of robots in the swarm to get a sense for how impressive it is.
Localization: Each of these autonomous rocket engines navigates to the proper place on the Nauvoo before clamping on. Navigating with respect to a large craft is difficult because most human crafts are pretty featureless. If you just look at the side of a battleship, it’s really hard to get a sense for where on the battleship you are. You have to do a combination of computer vision and odometry to figure it out. In this case the robots might be able to localize against each other to figure out where they are next to the Nauvoo, but that’s also something we haven’t quite figured out how to do yet.
Attachment: In space operations, you’ll sometimes hear the term RPOD for rendezvous, proximity operations, and docking. RPOD activities are very difficult, because you want to make sure the spacecraft don’t collide instead of docking. Part of this is the localization problem above, but part of it is also just how do you attach to the spacecraft? When the two spacecraft are designed to dock, this is kind of easy. We do it all the time when a new craft docks with the ISS. When the craft you’re docking with wasn’t designed for that, it’s much harder. We’ve only successfully done this once, when a Northrup Grumman craft docked with a satellite earlier this year.
Control: Finally, once the swarm of robots is attached to the Nauvoo in all the right places, they fire up their engines to reorient the thing. The control problem here is staggering. The Nauvoo is enormous. It’s probably filled with some leftover propellant, some water, and a lot of gases. That means it’s going to slosh as it moves, so the dynamics of the Nauvoo will change over time. Each robot needs to fire its engines at precisely the right time, for precisely the right duration, in order to get the Nauvoo going where it needs to go. They need to coordinate that firing, while also learning in real time how the Nauvoo actually responds to the thrust.
The reason I find all of this so impressive in the show is that we can almost do all of it. We’re actively getting closer to being able to do this, but every part of it is still outside our grasp.
When I see the med-tech that they have, my brain just fills it in as magic and moves on. I don’t know enough about biology or medicine to know how likely it is that we can cure cancer or hypoxic brain injuries using some arm-cuff. It’s cool, but it’s not inspiring since it feels like I can’t have it.
The space robotics in the Expanse is both cool and inspiring. We can get there, and it’s going to be amazing.
The Theory that Would Not Die starts out strong. This history of Bayesian thought by Sharon Bertsch McGrayne was recommended to me after I finished reading a biography of Claude Shannon, and I was pretty excited to read about how Bayesian thought developed before and after Shannon.
The first few chapters were a great introduction to the Reverend Thomas Bayes, to Pierre-Simon Laplace, and to some of the controversies of the early 1800s. Going into this book, I thought that I understood the origin of Bayes’ rule, and just had to learn about how it became popular now. My preconception was exactly backwards.
The myth of Bayes rule is that Bayes himself created it to address a question from David Hume about the existence of god. Hume claimed that our experience of the world says there can’t be miracles. Since we’ve never seen a miracle, if someone reports one we should always believe they’re mistaken (or lying). Bayes supposedly created his formula to prescribe exactly how much hearing about a miracle should increase our belief in god.
It turns out that there’s very little evidence that Bayes was thinking about that when he created his rule. He wrote a single paper about his rule, in the form of a probabilistic thought experiment involving tossing balls onto a table. That paper was published after Bayes died, along with some religious interpretations of it written by Bayes’ friend who found that paper in Bayes’ effects.
At this point, everyone forgets about it. Pierre-Simon Laplace, facing some very complicated data analysis problems in astronomy and biology, re-invents something very similar to Bayes rule a few decades later. It was Laplace, and not Bayes, who really popularized the idea of “the probability of causes” for the first time. He used it extensively for many of the problems that he faced, and only learned about Bayes’ paper by chance. Apparently Bayes’ prior probabilities (always equal odds) were new to Laplace, and Laplace then incorporated that idea into Laplace’s formulation.
After Laplace died, few people used his methods. There seems to have been some form of smear campaign against Laplace, with people actively avoiding methods he’d created. It wasn’t until the world wars that people started using the probability of causes again.
From WWI up to the present day, the military seems to have been a great user of Bayes’ rule. While statisticians and other academics were debating the merits of Bayes’ equal prior and finding it groundless, the militaries of the world were using Bayesian updating in everything from aiming guns to cracking codes. The military used it because it worked, the academics rejected it because they couldn’t see how it could make sense.
There were some notable academics who embraced Bayes’ rule around this time, especially Turing and Shannon. The book gives a pretty good overview of what Turing accomplished. I was left even more impressed with Turing after this, and even more upset at his treatment by Britain after the war. The book unfortunately didn’t really go into detail on Shannon’s use of Bayes’ rule.
During WWII, breaking German and Japanese codes was crucial to the war effort. The British didn’t really understand that cryptography had advanced since the 1800s, and had to be given the solution to early Enigma cyphers. Polish mathematicians had managed to crack it before the war began. Britain then hired Turing to expand on the Poles’ work, and he basically created modern computing in order to do it. A large part of his work was generating likely priors for different messages. Then using Bayesian updating to determine the rest of the message. After the war, all of his work was made confidential and Turing sworn to secrecy. He was later hounded into suicide by the British government.
After this period, a lot of arguing happened. That’s my best summary of the rest of the book. Many of the Post-WWII chapters were just chronicles of the arguments between people I’d never heard of before.
Each chapter was nominally about some use of Bayes’ rule in history. For the period after WWII, these chapters were arranged moderately chronologically so you could see how Bayes’ rule was rejected and embraced in various times and places. That overall structuring makes sense, so it’s unfortunate that the book didn’t work at all.
The book really played up the personalities of the people involved, and ignored the actual math to a large extent. McGrayne avoided in depth discussions of the math. There was maybe a handful of equations in the entire book. For a history of math, that’s pretty unhelpful. I was hoping to understand how the theory was developed, how new pieces that made Bayes’ workable in the modern world actually worked. Instead I got to read pages and pages about how various people were all jerks to each other.
The emphasis on what Bayes’ rule was used on, and the people who used it, also caused the book to feel very chaotic. The chapters were nominally in historical order, but the later chapters especially jumped around a lot in the careers of various people. I ended up reading about someone in one chapter for three pages, forgetting about him for 50 pages, and then seeing him again in another chapter with the assumption that I would still remember why he was important. I went into this book looking for a high level overview of a theory’s development, and instead of got the knitty-gritty back and forth between dozens of people over the course of decades. For me, this level of detail obscured the higher level points I was reading for.
I would have loved to see more discussion of the math. More simplified examples of what the people were actually working on, and how they were trying to do it. More equations in my math book, in other words.
I was also pretty surprised by what the book focused on in later chapters. It discussed Kalman filters only tangentially, in spite of the fact that they are an incredibly useful and common application of Bayes’ rule. I was waiting for the Kalman filter chapter with baited breath, and it never came. Instead I just got one sentence about how Kalman himself claimed that his filter wasn’t Bayesian at all.
This is such a missed opportunity! The book spends pages and pages talking about how hard it was for Bayesians to get recognized, and the little arguments between Bayesians and frequentists. Then it can’t spend a single page talking about the Kalman filter or why Kalman didn’t think it was Bayesian? The Kalman filter led the development of a huge family of Bayesian filters and models that are used in all of aviation today. Instead we get an entire chapter about some rando who got sent to Europe to look for a submarine. That’s cool and all, but what about the entire space program?
The lack of discussion on Kalman filters, throwing mathematical terms around without helping the reader understand them, the lengthy digressions into tiny spats between statisticians. All of this makes me question how the topics the book focused on were chosen. I’m left wondering whether I actually got a useful history of Bayesian thought, or just the tidbits that this author was particularly interested in.
This was disappointing, as the first few chapters were so good. My recommendation: read through to the end of WWII, then find a different book.
A friend on facebook recently asked for examples where people believed something wrong on purpose, just to improve their lives in some way.
While the idea seemed strange to me at first, I’ve slowly come to realize that there’s something similar that I’m doing in my thinking about my kids. And I think that thing is actually very important to raising my kids well.
Unlike the original request for examples, I’m not trying to believe something I know in my heart is untrue. Instead, I’m actively trying to avoid learning certain things about my kids. Or perhaps it would be better to say that I’m actively avoiding trying to build certain models about my kids.
Self-Fulfilling Models
My kids are very young, only two and a half right now. That means that there’s an enormous amount about who they are (or will be) as people that is unknown right now. Will they be interested in arts or sciences (or both)? Will they be introverts or extroverts? Will they like science fiction or mysteries?
Our kids aren’t super messy when they eat. The main exception to that is yogurt. When we feed them yogurt, it gets all over their faces, their arms, their shirts. The yogurt gets everywhere. After they’ve finished eating it, I’ll come in with a cloth to clean them up. Doing this makes it really obvious that they’re using one hand more than the other. One hand is usually pretty clean, and the other is so covered in yogurt it looks like melted wax.
I actively try not to pay attention to which hand it is. I try to avoid putting together patterns about whether the messy hand changes each time they eat yogurt or not. I try to avoid pointing it out to them.
My goal is to let them develop their handedness, left or right, independently of my own preconceptions. I don’t want to push them to use a hand that they’re not interested in using, or to prematurely settle on using only one hand.
Especially now, during this time of covid-induced hibernation, my kids get the majority of their understanding of the world and what’s good from me. How I think about them influences how I treat them, and how I treat them has an outsized impact on how they grow. I don’t want my own peculiarities to unduly shape who they could be as people.
The importance of letting kids be themselves
Whether our kids are left handed or right handed isn’t a huge deal (but it was historically). On the other hand, there are some personal traits that will have a major influence on my children’s lives. I’m trying to avoid learning those or modeling them as well.
The biggest example of this is intelligence. There’s a whole argument about what “intelligence” means for kids, how correlated intelligence in one domain is with another domain, how it changes with age, and how easy it is to determine. I want to sidestep all of that by appealing to a twin study.
Specifically, a study of my twins. They’re fraternal twins, so genetically different but same environment. They look different and they act different. They also figure things out at different rates. One of my kids is much more verbal than the other, much faster in answering questions, and much better at remembering (or at least repeating) song lyrics.
In spite of how I try not to notice that disparity, it still surprised me when the disparity was disrupted. I taught the kids how to play “I spy…” the other day. The kid who is faster at answering questions and filling in song lyrics really struggled with understanding how the game is played or what the point of it was. The other kid, who is generally quieter and slower to answer questions, understood how the game is played immediately and joined in.
I’ve heard some parents talk about their kids as being “smart” or “slow”. I don’t think either of those models are very helpful to actually raising kids. To me, what seems most important is what would challenge a kid at any given moment. Regardless of what a kid is capable of now, the goal is still to raise the most competent, compassionate, and grounded kids that I can.
For me as a parent, it doesn’t matter if one kid is learning something faster than another. What matters is how I can help both of them learn and grow as effectively as possible. That’s going to be different for each kid, but my overall job is the same.
If I get wrapped up in comparing my kids to each other, or to some arbitrary “standard” development track, that makes it harder for me to do my real job of raising them.
On modeling humans
None of this is to say that I don’t think the idea of intelligence is useful (or similar summary measures like “compassionate” or “grounded”, for that matter). I actually do think summarizing a person as being “smart” can really help when you’re trying to figure out whether to hire person A or person B for a job. Or when you’re trying to decide what leader to elect. Or when you’re thinking about who you trust to have good information about something.
If I were a perfectly fair person, this would be less of an issue. If I were actually able to use my models of the world only when they were applicable, and ignore them when they weren’t applicable, then this wouldn’t matter. I could go ahead and think of one of my kids as left-handed, or estimate their intelligence right now, and not let it impact how I raised them.
But I am not perfectly fair. If I start modeling a person, my model of them will influence every thought I have about them. I can’t even avoid modeling them. When I notice someone answering a question quickly, that automatically leads me to thinking certain things about them. When I notice them usually using their left hand, I automatically label them left-handed.
This is why I actively try to avoid making certain observations about my kids. It’s why I actively try to avoid letting certain observations coalesce into models of them. I know my job, and it’s not judging them. It’s nurturing them. As a human myself, that’s easiest to do when I haven’t already decided what they’ll grow into.
PS
Just to be clear, I also think my kids are both very smart. And caring, creative, athletic, and cute. I’m so proud of them for all of that, but those adjectives aren’t useful when figuring out what games to play or what to teach them next.
A while ago I stumbled on the blog Acoup, which is mostly military history written by an Assistant Professor of history at NCSU. As I binged through the blog’s backlog, I stumbled on a series about Sparta that totally surprised me. Here’s a post I made about it on Facebook.
“When I read about real Spartan history recently, I was pretty surprised that they were only mediocre as individual warriors, they were terrible at warfare in general, and were incredibly brutal to their absolutely huge numbers of slaves.”
This started a fascinating argument about Greek history. It seems like everyone pretty much agrees that Sparta was pretty brutal to their lower classes (though I had had no idea about that until I read the blog posts). What people disagree about is whether they were good at war. This makes sense, given that it’s such a staple of popular culture. Some of the people in that FB discussion know way more history than I do, so I ended up unsure how to weight their statements against those of Acoup.
In the end, I remain pretty convinced by Acoup’s claims about Sparta’s (lack of ) prowess at naval and siege warfare, as well as logistics. Where I was left most confused was in the claims about hoplite warfare. As one of my friends mentioned in that FB argument:
“[W]e’re talking about putting down a lot of skilled contemporary analysis. The idea that [historical sources like Xenophon] were just suckered and there’s nothing to it is almost shockingly arrogant, given the scope of their capabilities and accomplishments. As far as I can tell essentially no contemporary sources are like ‘actually, the Spartans are bad and unimpressive’.”
The crux of the argument
everybody: Spartans were the best warriors in the world Acoup: Spartans society was horrible to live in and highly immoral by modern standards. Also they didn’t win very many wars. Me (on FB): Seems like Spartans were terrible at warfare FB friends: they were actually great warriors, and everybody in antiquity knew it
It’s easy to get side-tracked by these types of arguments. The overall idea of Spartans in pop culture is definitely that they’re peak warriors. When I argued with people who defend Spartan military acumen, I found that they fell back on hoplite battle as what they meant by that.
This feels a bit like a motte and bailey argument to me, where a push back on overall military competence gets rebutted with a much smaller claim. Maybe the people who defend the bailey (Spartans were awesome at war) are separate from those that defend the motte (Spartans were good at hoplite battles), but it’s hard to say.
In any case, I want to be clear about what question I’m trying to answer. I just want to know if Spartans won more battles than they lost.
If Spartans won most of the battles they fought, then I have to admit that they were better than their contemporaries. If they lost most of their battles, then they weren’t. If it was about 50/50, then maybe they were only average.
There’s a lot of minutiae that goes into this, because battles are never clean competitions between comparable forces. The Spartans that are most renowned were those who went through the agoge schooling (called Spartiates), but many in Spartan forces were helots who hadn’t had that training. How do we gauge those differences?
Similarly, Sparta often went to war alongside allies. Depending on time period, they allied with the Thebans, the Athenians, the Persians, etc. If we want to know how good the Spartiates were, we should discount battles where most of the soldiers on the Spartan side were from allied forces.
We should also look at how the Spartans actually won their battles. If they won pitched battles against a numerically superior opponent, then that’s good evidence that they were strong warriors. If they won against a surprised force that was much smaller than them, I’d take that as not arguing for their skill at arms.
Spartan military might waxed and waned over time. To do this right, we should give the most weight to the battles when they were strongest.
But all of that sounds like a lot of work. So I’m going to take a list of Spartan battles (this one from wikipedia), and just look at win/loss record. I think that’ll give a good first order approximation to their abilities. I’ll look at a few individual battles after that to get a sense for the more specific questions.
Overall Battle Performance
I made a table from Wikipedia’s list of Spartan battles, and you can find it at the end of this post.
I’m not a historian, and I don’t have the decade+ to become one to answer a question that is pure curiosity on my part. It seems pretty likely that the Wikipedia list isn’t comprehensive, but my naive estimation is that it probably contains the more well known and impactful of Sparta’s battles. If you know of a better list, let me know and I might update my analysis later (time permitting).
There were 35 battles on that list. Of those, they had 16 wins, 16 losses, and 3 ties. To me, that seems to indicate that they were mostly fighting people who were about as good at war as they were. By this measure, they certainly weren’t terrible at war (as I maybe mis-interpreted Acoup as saying). On the other hand, they aren’t the gods of war that pop-culture makes them out to me.
Individual battles
Having looked at how the Spartans did overall, it will also be instructive to look at a few individual battles and see why the Spartans won or lost. Here are a few important ones:
Battle of the 300 Champions
I find the battle of the 300 champions very useful for this argument. Sparta and Argos were going to war, but they didn’t want to waste all their armies. They decided they’d have 300 men of each side fight, and that would determine who won the battle. The rest of the militaries withdrew to prevent interference, so it was really just these two groups of 300 people each.
I’m not sure who was chosen to be in the Spartan group of 300, but it seems a safe assumption that it was primarily Spartiates. Those Spartans who had been through the Agoge and were the best warriors Sparta had to offer.
This gives one of the most pure comparison points available for Sparta’s military prowess (at least as of 546BC). It’s a pitched battle between equal numbers of people, so obviously whoever wins is better at battle.
But it infamously came down to a tie. Technically two Argos soldiers survived and one Spartan soldier survived. This argues pretty strongly against the Spartan exceptionalism theory.
On the other hand, since the outcome of the battle of 300 was so in doubt, Sparta and Argos went ahead with the full battle that they’d tried to avoid earlier. Spartans defeated the Argos in this larger battle.
Another interesting tidbit is that Argos challenged Sparta to a rematch 100 years later, which Sparta declined.
Battle of Sepeia
The battle of Sepeia, also between Spartans and Argives, was a total victory for the Spartans. The Spartans completely devastated the Argive military.
Did the Spartans win through superior skill at arms? No, the Spartans ambushed the Argives while they were all eating lunch.
I don’t want to knock this tactic. All’s fair in war, as they say. But it doesn’t seem to be strong evidence that the Spartans were great hoplite soldiers, as it’s much easier to destroy an opposing force when their hands are full of food instead of weapons.
The Athenian Sicilian Expedition
During the Peloponnesian War, the Athenians invaded Sicily. Over the course of the expedition (which involved many battles), the Spartans and their allies completely destroyed the Athenians’ expedition.
Athens lost 10000 hoplites and 30000 oarsmen. That was a huge blow to their military. As Wikipedia says, “the defeat of the Sicilian expedition was essentially the beginning of the end for Athens”. After this defeat, many previously neutral parties allied with Sparta.
In a counterfactual world where Athens hadn’t invaded Sicily, they may have won the Peloponnesian War. Even if they had invaded, if they’d withdrawn when they realized they were losing they could have saved some of their soldiers to fight in later battles. My (naive) reading of this battle is that Sparta would have had a much tougher time winning the war if Athens hadn’t been defeated here.
Should we give Sparta the credit for this? There were definitely Spartans involved in the Sicilian fight against Athens. It’s hard to get a sense for numbers here, but my take on the Wikipedia article is that it was mainly Syracusans who fought off the Athenians, and they were just assisted by the Spartans. In other words, the Syracusans may have been one of the main reasons that the Spartans won the war.
The Spartan Mythos
Based on that list of battles, I have to revise my original assumptions. Spartans weren’t terrible at war. They also weren’t obviously superior at it. If I had to summon a warrior through time to organize my assault against a great evil, it’s not clear I should choose a Spartan over an Argive (I would obviously choose Alexander the Great, a Macedonian).
Why then is Sparta held up as a core of military mastery? I honestly think it’s because they liked war so much. They had a whole school devoted to teaching their kids to be warriors. It might not have helped them to conquer and hold their neighbors (which they obviously wanted to do). It did impress all of their neighbors though, and it made it clear what Sparta valued.
People in middle class America don’t fight hoplite battles. When we go to war, we have the best equipment and the most people. Our soldiers don’t necessarily need to emulate great generals or ancient soldiers, they just need to have values that work well with military discipline. Our civilians don’t even need that much, they mostly just want to feel connected to a sense of physical pride and motivation. The Spartan mythos provides these things, even if it doesn’t have much to do with Sparta itself.
I also think the Spartan mythos was pretty useful to Sparta itself. It seems pretty clear that Sparta was drinking it’s own koolaid. A friend asks the very reasonable question:
“The Spartans were, by all accounts, backwards, agrarian and few in number. But they seem to have had an outsized influence in the geopolitics of the day.”
I think recent American politics have shown that you don’t necessarily have to be skilled and exceptional to have a big impact on something. What really worked for Trump was just a willingness to push for what he wanted, and keep pushing regardless of what other people said or who might have been a better fit. It seems pretty clear the Spartans would have supported that mindset.


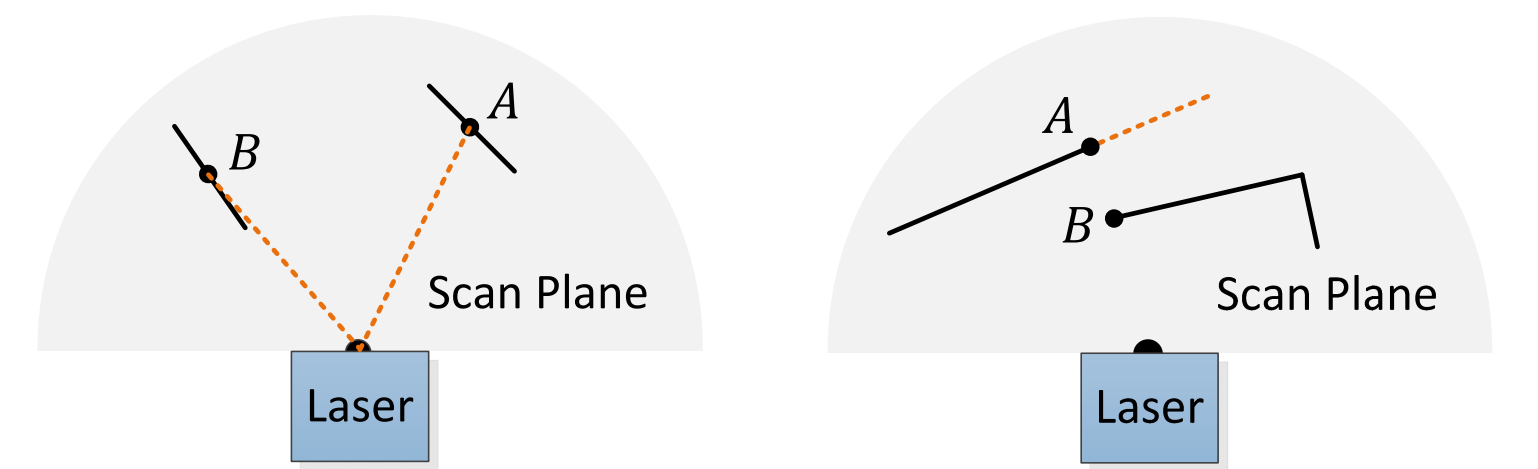






{kind=link}