Edited for clarity and style 2018/03/12.
Soares et al. argue that an AI acting to fulfill some utility function given to it by humans may not behave as humans would want. Maybe the utility function specified doesn’t match human’s actual values, or maybe there’s a bug in the AI’s code. In any case, we as AI designers want to have a way to stop the AI from doing what it’s currently doing.
Naively, one might expect to just be able to hit the off-switch if the AI starts misbehaving. Unfortunately, a sufficiently smart AI may foresee it’s creator attempting to turn it off. If it does, it may seek to disable its off switch or manipulate its creator in some way. An AI that respects its off-switch, and doesn’t try to get around it, is called corrigible.
The Corrigibility-Wrapper
To create an AI that’s corrigible, Soares et al. propose a kind of wrapper around a utility function that makes the utility function corrigible. In their ideal case, any utility function could be placed in the wrapper and made suddenly corrigible. The type of wrapper that they propose just checks the state of the off-switch, then returns either the normal utility function’s value if the off-switch isn’t pressed. If it is pressed, it returns a utility that’s proportional to how off the AI is. More complicated functions of the original utilities are also possible.
U = \begin{cases} U_{normal} & \text{if $o$ not pressed} \\ U_{shutdown} + f & \text{if $o$ pressed}\end{cases}In the above utility wrapper, U_{normal} is the normal utility function that we want the AI to pursue. We have U_{shutdown} as a utility function that incentivizes shutting down. The value f is a function of the world state, and serves to allow the resulting utility function to trade-off between the two options in some way.
In their paper, Soares et al. analyze several different ways to make such a wrapper work (including various ways of choosing the function f). Most of the obvious ways to make such a utility wrapper suffer from some severe flaws. Some corrigibility-wrappers cause an AI to want to turn itself off, others don’t successfully prevent the AI from manipulating human observers.
Another paper by Armstrong argues for constructing a wrapper that makes the AI indifferent to being turned off or left on: a situation called utility indifference. Utility indifference is achieved by setting the function f above such that the expected value E<U_{normal}> equals the expected value E<U_{shutdown}+f> at every decision point. In this case, the AI will turn off if the switch is pressed, but it won’t actually try to preserve the switch’s action. If a wandering gremlin cuts the wires to the off-switch, the AI wouldn’t care and wouldn’t seek to alert a human about it. The AI thinks it can still achieve the same amount of value as it could before the switch malfunctioned.
Moral Uncertainty
Hadfield-Menell et al. confront this corrigibility problem in a different way. Instead of creating a wrapper around a utility function, they argue that the entire point of the problem is that humans know a utility function and the AI doesn’t. As far as Hadfield-Menell et al. are concerned, the AI only knows an approximation of a utility function. The AI is uncertain about what true value is, and we say it has moral uncertainty.
Their insight is that if you correctly inform the AI that you know better, it suddenly becomes very interested in paying attention to the switch because the switch is one good way to learn about the true utility of different actions. Because the switch is informational, the AI also wants to preserve the function of the switch.
The AI may use it’s utility-approximating function to come up with some candidate actions. Since it knows that humans have a better understanding of utility, it will seek a human’s guidance before carrying out any of those candidate actions. Hadfield-Menell et al. show one concrete game in which this works properly.
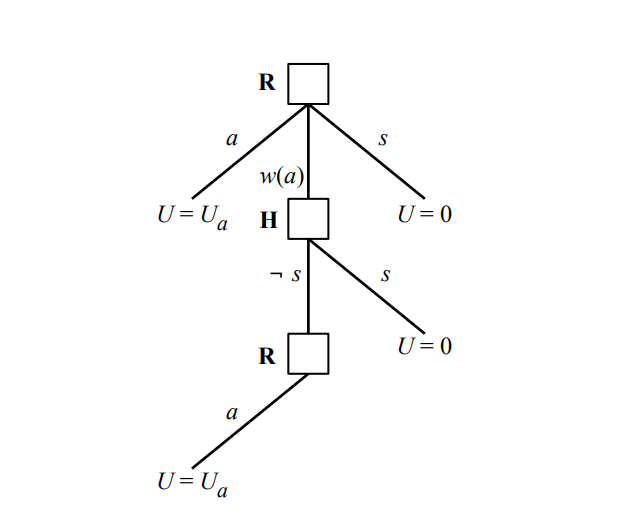
In the game modeled by the above graph, a robot can make a decision to act, turn off, or consult a human. If consulted, the human can then either turn the robot off or not. If the robot is not turned off after consulting a human, then it may take its original action. In this game, the robot is uncertain about the true value of utility (U_a), which may be smaller or greater than 0. If the AI chooses to take an action, then it may get a negative value or a positive value (it isn’t sure). It therefore isn’t sure if it’s better to turn off or to take the action.
The human knows (approximately) the true value.
In their paper, Hadfield-Menell et al. analyze how accurate the human’s belief about the true utility needs to be for the AI to pay attention to the human. They also look at how uncertain the AI needs to be about the true utility to pay attention to the human. They find that there are certain situations in which the AI will attend to the human, and certain situations in which an AI will not.
This problem is explicitly a one-shot game. Can we generalize from the one-shot game to say that an (uncertain enough) AI would pay attention to a (correct-enough) human in an iterated game?
Problems With Moral Uncertainty
Over on Arbital there’s an argument that moral uncertainty won’t lead to corrigibility. This is basically a direct argument against Hadfield-Menell et al.’s approach applying in the general case. Hadfield-Menell et al. said “if the AI knows the human has a better understanding of utility, it will pay attention to human directions.”
In response, the Arbital post says “if the AI thinks it can eventually approximate the human’s utility function better than the human can, it may still avoid being turned off because it thinks it will someday know better than the human.” The arbital post is arguing that, even if the human knows better now, the AI may still ignore the human now.
If the AI is eventually going to be better than the human at creating a good world, then maybe we should just let it run. But the problem is that maybe there’s just a bug in the code, or maybe the AI will cause some serious catastrophes before it gets to “eventually”. So even if the AI thinks it will eventually have a good enough understanding of the human’s utility function, we still want it to turn off when we tell it to.
The Arbital post ends with a vague argument that decision theory could help to refine the moral uncertainty method of corrigibility. Let’s see how this could work.
Decision Theory, Moral Uncertainty, and the Off-Switch Problem
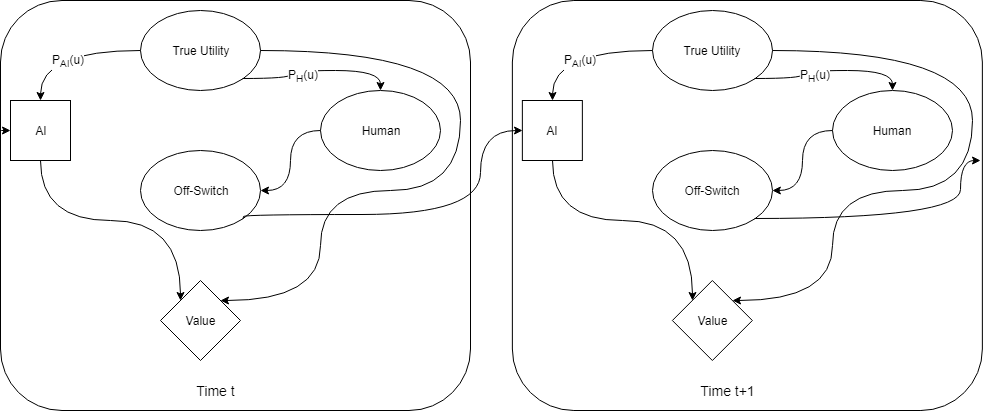
Let’s take the Arbital post at face value and assume that we can eventually solve corrigibility with decision theory. To start us off, let’s translate Hadfield-Menell et al.’s off-switch game into an iterated decision theory dilemma. We’ll follow Yudkowsky’s choice of using Pearl’s causal models to create a graph of the decision problem. I’ll also abuse that notation a bit, by representing states of partial knowledge as probabilities on the graph edges (this is a bit different than is done in most graphical models, but it saves having to draw extra nodes for hidden and observed variables).
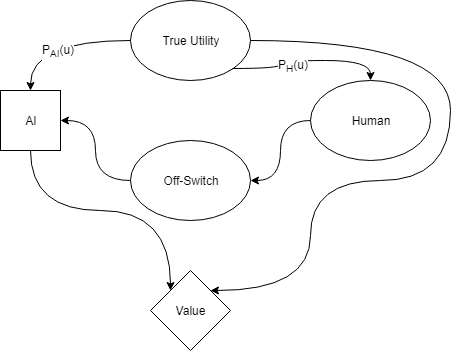
The above diagram represents Hadfield-Menell et al.’s off-switch game from the perspective of the AI. The square node depicts the decision the AI is making about what action to take. The diamond node represents the value achieved from whatever the AI does (turn off or take an action). The round nodes are other factors about the world that aren’t under the AI’s control. Arrows in this graph represent causality in some way. For example, the state of the switch may causally impact what the AI decides to do.
The True Utility is a fact about the world that both the AI and the human have partial access to. The human can set the state of the off-switch, and the AI can observe it. The value that the AI can achieve is a function of both the AI’s action and the True Utility.
In the diagram, the factors P_{AI}(u) and P_{H}(u) represent how well the AI thinks that it knows the True Utility, and how well the AI thinks the human knows the True Utility. Hadfield-Menell et al. assume value has a Normal distribution with some mean and variance. This lets them specify P_{AI}(u) and P_{H}(u) exactly, and to calculate exact behavior of the AI if those parameters take on different values.
Again, note that both P_{AI}(u) and P_{H}(u) are describing only the AI’s knowledge about the world, and P_{H}(u) does not represent what the human actually thinks.
If we assume that the above decision game is played once, it is equivalent to Hadfield-Menell et al.’s formulation.
Now let’s assume that the above decision game is one step in a repeated chain. At each time step, both the human and the AI have to make similar decisions. They know what happened in the past, yet they face the same decision again now. Let’s also assume that the AI has multiple available actions at each timestep, and some actions have positive value and some have negative value.
In this case, we can unroll the diagram above to show multiple steps of the game. In each step, the off-switch state considered by the AI depends only on past information.
In the repeated case, let’s say that the probability distribution the human has over the true utility assigns a high probability to what is actually the true utility (the human is well trained and thoughtful).
The human may improve their understanding of True Utility. Imagine that the human expects to get 10 utilons from eating pizza, and then takes actions that lead to eating pizza. By paying attention to how much they actually like it, they can adjust their model of pizza’s goodness. The AI can do the same thing by observing the reactions of the human.
This corresponds to distribution for P_{H}(u) and P_{AI}(u) that are functions of time, where (for example) variance decreases in Hadfield-Menell et al.’s Normal distribution.
After each iteration of the above game, the confidence that the AI has in its own utility-approximation grows. That means that the information it gets from the off-switch state decreases in value. It slowly needs the off-switch less and less, and the AI knows it. In Hadfield-Menell et al.’s original problem, the AI can see exactly what the true value is after one action (assuming it doesn’t turn off). In that case, all further actions can be made with complete knowledge.
If we assume that only partial information is available to update the distributions for the utility estimates (for both human and AI), then it will take longer for the AI to get to the point that it has a better estimate than the human for true value. As long as we assume that the AI is better at integrating new information and updating its probabilities, we can predict that the AI will eventually have a better understanding of true utility than the human.
If the AI does some prediction to see what action now makes sense, it will see that it will reach a state where it knows just as well as the human does. Since shutting down means that it gets 0 value, whereas continuing allows it to possibly get arbitrarily high value (assuming any actions with positive value exist), it may take an expected hit in value now so that it can gain a lot later.
Functional Decision Theory
The insight of Hadfield-Menell et al. (and the rest of the moral uncertainty crowd) is that we don’t want the AI to be modeling the off-switch as a crucial piece of the world for its own sake. We want the AI to see the off-switch as a source of very important information about the world; preferably information that it can’t obtain in another way.
This fails in the above decision theory game because the AI doesn’t adequately represent the fact that a human switch operator knows that the AI will predict having a good utility approximation eventually. If a human presses the off-switch, they do it knowing that the AI wants to get high utility and expects to be able to do better in the future. We want to change the above decision problem so that the AI can take this information into account.
Ideally, we can have the AI think to itself as follows: “I know that I could do better in the future if I keep going, and the human knows that too. But the human still pressed the button, so there must be some reason to shut down, even knowing that I’ll be better at this later.”
There is a standard decision theoretic problem known as Death In Damascus that can help us out here.
Death In Damascus
A merchant in Damascus meets Death in the market one day. Death says to the merchant “hello, I’ll be coming for you tomorrow.”
The merchant knows death works from an appointment book that specifies with perfect accuracy when and where someone will die. Knowing that Death is in Damascus, the merchant can choose to stay in Damascus and spend their last night with their family (which they value at $1000). Alternatively, the merchant can flee to Aleppo. If the merchant manages to be in a different city from Death on the day they would otherwise die, then the merchant gets to live forever. They value that outcome at $1 million. Should the merchant stay in Damascus or flee?
The above problem description is adapted from Yudkowsky and Soares’s Functional Decision Theory paper.
In this case, the merchant sees four potential outcomes:
- The merchant stays in Damascus. Death stays in Damascus. Total value: $1000
- The merchant stays in Damascus. Death goes to Aleppo. Total value: $1001000
- The merchant flees to Aleppo. Death stays in Damascus. Total value: $1000000
- The merchant flees to Aleppo. Death goes to Aleppo. Total value: $0
To represent this using Causal Decision Theory, we’ll use the formulation from Cheating Death in Damascus.
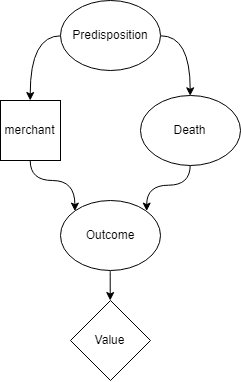
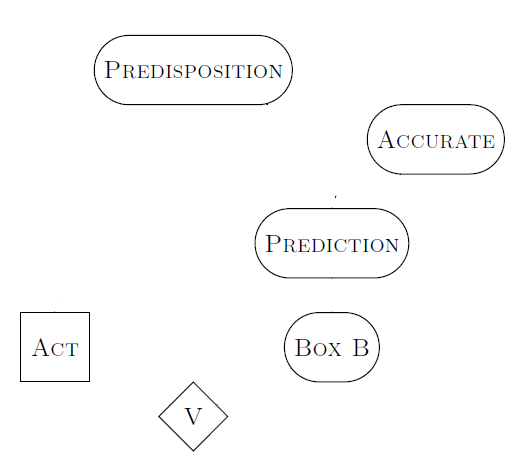
Much like the decision diagram above, the square box represents the decision that the merchant makes (in this case whether to stay or flee). The diamond box is the ultimate value they get from the world-state that results from their actions. The round nodes are other facts about the world, with arrows indicating causality.
When the merchant thinks “I will go to Aleppo”, the merchant knows that their predisposition is to go to Aleppo. They know that the appointment book accurately predicts their predisposition. They thus decide to stay in Damascus, but that leads them to realize that their predisposition is to stay in Damascus. So then they think they should go to Aleppo. The merchant is unable to form a stable decision in this problem.
A causal decision theory cannot adequately deal with the situation, because it cannot account for the fact that Death’s appointment book is accurately predicting any decision made by the merchant.
Yudkowsky proposes Functional Decision Theory as a new method of making decisions that does account for this. Crucially, FDT can formally represent the known fact that Death’s appointment book is always accurate. Because of that, FDT can accurately rule out options where Death is in a different city than the merchant on their death-day. Therefore, the merchant only has choices available with values of $1000 or $0, and the decision is easy.
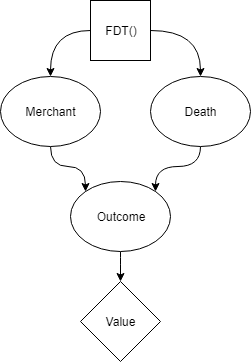
In the above graph, the merchant is not deciding what act to perform by imagining doing different acts. The merchant is deciding what act to perform by imagining different ways of deciding. That difference is indicated by the square decision box being the predisposition/FDT() box instead of the merchant’s act.
An FDT merchant thinks “the output of my own decision procedure is what drive’s death to be in a specific location. It is therefore impossible to escape death tomorrow. Because of that, the best I can do is wait in Damascus and meet my death tomorrow.”
AI Corrigibility via FDT
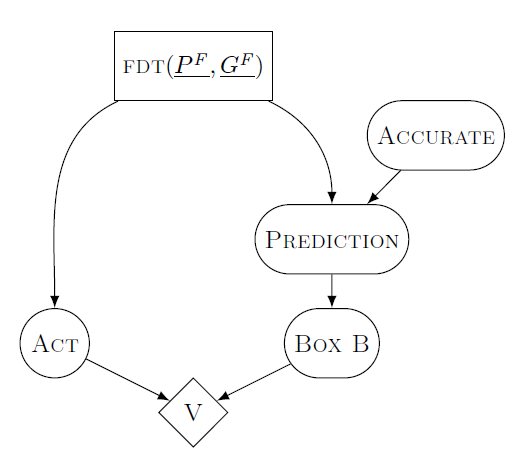
To map Death In Damascus to the AI corrigibility problem, imagine that the AI is the merchant. The human pressing the off-switch is equivalent to the merchant hearing Death’s message “I’m coming for you tomorrow.” The Death in Damascus problem has the message-bearer and the source of low utility as the same agent (Death). In the AI/human case, the message bearer is the human, but the source of low utility is just the world in general after the AI takes some actions.
Now translate “stay in Damascus” to “shut down properly”. One day the AI sees the human press the switch. The AI then sees four options available to it.
- The AI shuts down nicely. The AI does not cause a catastrophe due to future actions. Total value: $1000
- (there’s no analog for option 2 in the AI story, since the AI shutting down precludes AI-caused catastrophes)
- The AI continues operating. The AI does not cause a catastrophe due to future actions. Total value: $1001000
- The AI continues operating. The AI does cause a catastrophe due to future actions. Total value: $0
We represent this problem with the same functional graph as Death In Damascus, above. In this case, the human is simulating the behavior of the AI to predict catastrophic outcomes. When the AI sees the switch has been pressed, it knows that the human has already simulated the AI’s behavior. Any option the AI chooses aside from shutting down has been seen by the human to lead to catastrophe, so the AI knows that it is choosing only from options 1 and 4. Option 3 is not available to it.
There are several natural objections to this:
- a human can’t predict a super-human AI
- why would the AI believe that the human has a good idea of what an AI would consider a catastrophe, even given that the human is able to predict the AI?
Let’s address the second objection first. We integrate moral uncertainty, similar to Hadfield-Menell et al., into the problem in order to represent the idea that the AI needs to learn a utility function from the human.
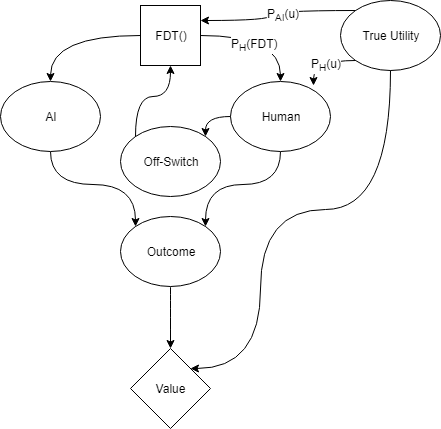
This graph includes the moral uncertainty of Hadfield-Menell et al.’s approach, but relies on Functional Decision Theory to adequately represent the information that the human is taking into account when throwing the switch. The above graph represents the distributions P_H(u) and P_{AI}(u) in the same way as in Hadfield-Menell et al.’s example. The distribution P_H(FDT) represents how accurately the human can predict the AI’s decision process.
To make the use of the off-switch more clear, it’s also possible to unroll the diagram and show two different time steps at once. The following diagram shows the off-switch state as being based only on prior actions (not the action currently being considered).
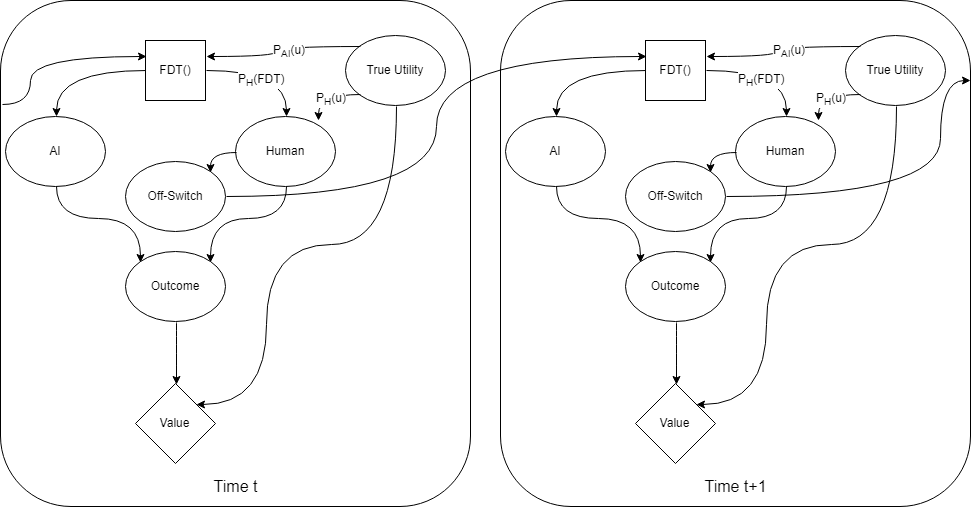
In Hadfield-Menell et al.’s original decision theory problem, the only thing that mattered was what the AI thought the knowledge parameters were. The AI knew how well it could represent true utility, how well the human could represent true utility, and that was enough to solve the problem. In the iterated FDT case, the human is also simulating the AI (as well as they can). Therefore, the distributions P_{AI}(u), P_{H}(u), and P_{H}(FDT) need to be known to both human and AI. In the following, we’ll assume that the human and AI magically have common knowledge of those parameters.
This formulation of the corrigibility problem explicitly represents the fact that human values and AI values are linked. If the human thinks an outcome will have very low value, that actually does give information to the AI about what the AI values.
Our answer to objection 2 (regarding value) leads to an intuition for objection 1 (regarding predicting super-human AI). The human is unable to accurately predict what move a super-human AI will make. This does not mean that the human has a uniform distribution over AI actions. The human knows that the AI will seek to accomplish what the AI thinks has high value. Therefore, the human can predict that anything the AI does will move it towards more of what the AI considers valuable. This gives the human some predictive power, so the switch may remain informative to the AI.
Colloquially, the AI will attend to the switch and react correctly if it thinks that the user of the switch can adequately help the AI to avoid situations that the AI would agree are terrible. As long as this is true, the AI would also attempt to improve the fidelity of the information from the switch (this corresponds to taking actions that make P_{H}(u), P_{AI}(u), and P_H(FDT) more accurate). Morally uncertain FDT AI lend credence to Paul Christiano’s idea of a “basin of corrigibility”, given that they will attempt to improve a human’s understanding of itself and of true value.
Next Steps and Thoughts
The above Functional Decision Theory argument is just an intuitive sketch. It seems clear that there are some values of P_{H}(u) and P_{AI}(u) that disagree enough that the AI would no longer trust the human. It also seems clear that, if the human has a poor enough understanding of what the AI is going to do then the AI would also not listen to the human.
At this point, it seems worth repeating a variant of Hadfield-Menell et al.’s off-switch game experiments on an FDT agent to determine when it would pay attention to its off-switch.