With ChatGPT taking the world by storm, it’s obvious to everyone that transformers are a useful AI tool in the world of bits. How useful can they be in the world of atoms? In particular, can they be used for robotics control. That’s the question answered by Google’s new paper on the Robotics Transformer 1 (RT1).
GPT and other large language models use collections of text, generally scraped from the internet, to learn how to do text completion. It turns out that once you know how to write the endings of sentences, paragraphs, and articles, then you can use that skill to answer questions. In fact, you can “complete the text” in a question/answer format so well that you can do pretty well on the SATs. If you can use transformers to get into college, can you also use them to walk (or roll) from classroom to classroom?
RT1 Overview
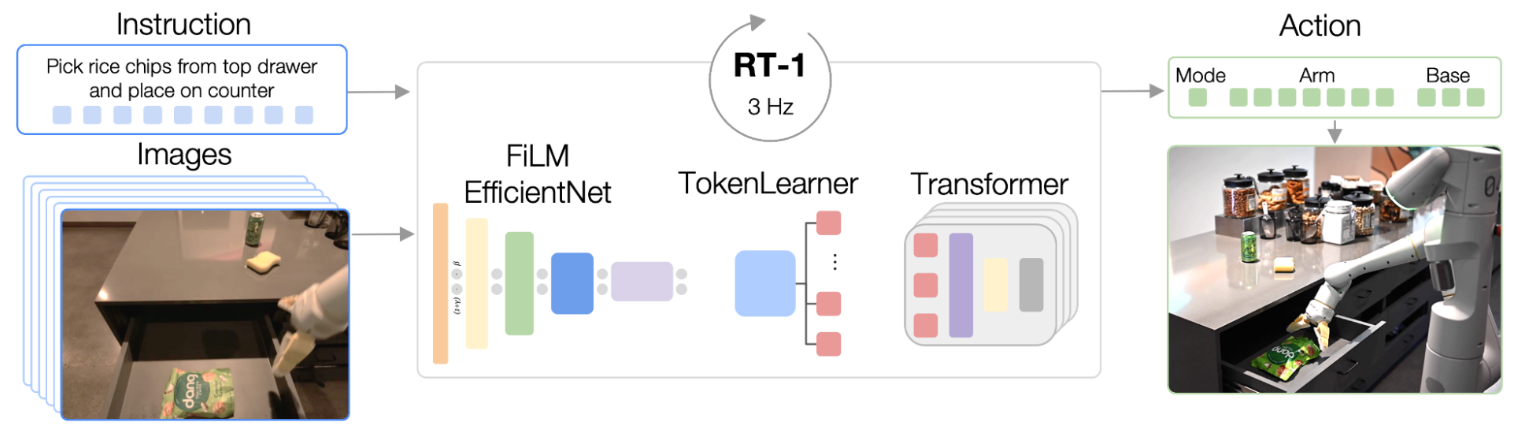
RT1 differs from GPT in that its input is camera images and text instructions (instead of just text). Its output is joint-angles (instead of more text). While GPT could be trained on text that people wrote for its own sake and put on the internet, RT1 was trained on recordings of robot tasks created for the sake of training it.
The goal is to create a network that can perform simple actions like “pick up the bottle” or “go to the sink”. These actions can then be chained (using something built on top of RT1) to create very complex behaviors.
The inputs to RT1 are a short history of 6 camera images leading up the current moment and the task description (in english). These camera images are sent to a pre-trained image recognition model. They just used EfficientNet, which they’d built a few years ago. Instead of taking the image classifications from their image recognition model, they take the output of a spatial feature map. I think this is the equivalent of chopping off the output portions of the image classification network and observing an internal layer. This internal layer encodes useful information about what’s in the image.
The internal layer encoding from EfficientNet is 9x9x512 values. They take those values and encode them into 81 tokens. I think that this means they just treat each 512 value array as a token, and then feed that into FiLM (PDF warning) layers to pick out useful information from each token based on the text description.
FiLM is a method of modifying network weights based on outside information. The overall idea (afaict) is that you have a FiLM generator that looks at outside information (in this case the task description in English) and outputs some coefficients. Then you have a FiLM layer in your neural net that takes these coefficients and uses them to tweak each value. In a fully connected network, every node in one layer impacts every node in the next layer. In a FiLM layer, each node in the prior layer impacts only one node in the FiLM layer.
Since the input to FiLM is the pre-trained EfficientNet, the only thing that needs to be trained at this point is the FiLM generator itself. The FiLM generator gets trained to modify the tokens according to the text input.
Once tokens are modified according to the text, they’re compressed by TokenLearner, another off-the-shelf project from Google. TokenLearner takes the tokens output from FiLM and uses spatial attention to figure out what’s important in them. It then outputs only 8 tokens to be passed to the next layer of the network. It selects 8 tokens for each of the 6 input images.
After the tokens for each image have been created, the data is sent to the transformer layers. RT1 uses 8 self-attention layers. In GPT, the attention is “temporal” in the sense that you’re attending to how early characters impact the probability of later characters. In RT1, the attention is both spatial and temporal. RT1 uses self-attention to figure out how pixels in one location and time impact the probability of pixel values in other locations and times.
Outputs are arm and base movements. Arm movements are things like position in space (x, y, z), orientation in space (roll, pitch, yaw), and gripper opening. Base movements are position and orientation as well, but (x,y) and (yaw) only. Each element in the output can take only one of 256 values. The output also contains a “mode” variable. Modes can be either “base moving”, “arm moving”, or “episode complete”.
Each of those 256 values per output element is a single output node of the network. There are thus 256 output nodes per dimension (along with the three nodes for mode). The actual values for each of these output nodes are treated as a probability for what action to actually take.
Training
The training data problem in robotics is a big deal. GPT-3 was trained on about 500 billion tokens. Since RT1 had to be trained on custom training data, it’s dataset was only 130 thousand episodes. I didn’t see how many total token were used in training in the paper, but if each episode is 1 minute long that’s only 23 million frames of data.
To get the training data, Google had people remote-control various robots to perform certain tasks. Each task was recorded, and someone went through and annotated the task with what was being done. It seems like the goal was to get recordings of tasks that would be common in the home: taking things out of drawers, putting them back, opening jars, etc. Those 130 thousand episodes cover 700 different types of task.
The paper makes it clear that they expect generalization in competence between the tasks. This requires tasks to be similar enough to each other that generalizations can be made. The RT1 data included tasks such as “pick apple” or “pick coke can”, so the similarity between their tasks is pretty clear.
The paper also includes some experiments on simulated data. They add simulated data to the experimentally collected data and find that performance on the original “real data” tasks doesn’t decrease. At the same time, performance on sim-only tasks does increase. This is great news, and may be a partial solution to the sim2real learning problem.
The paper was a bit light on details about the training itself. I’m not clear on how much compute it took to train. Many components of the model come pre-trained, which likely sped things up considerably.
Performance
With GPT-3, performance is generally just “how reasonable does the output text sound?”. In robotics there’s a more concrete performance criterion. Did the robot actually do the thing you told it to do? That’s a yes/no question that’s easier to answer.
Google measured RT1’s performance on tasks it had seen in training, tasks similar to those seen in training but not identical, tasks in cluttered environments, and tasks that take long term planning. In each of these categories, RT1 outperformed the comparison models that Google was using.
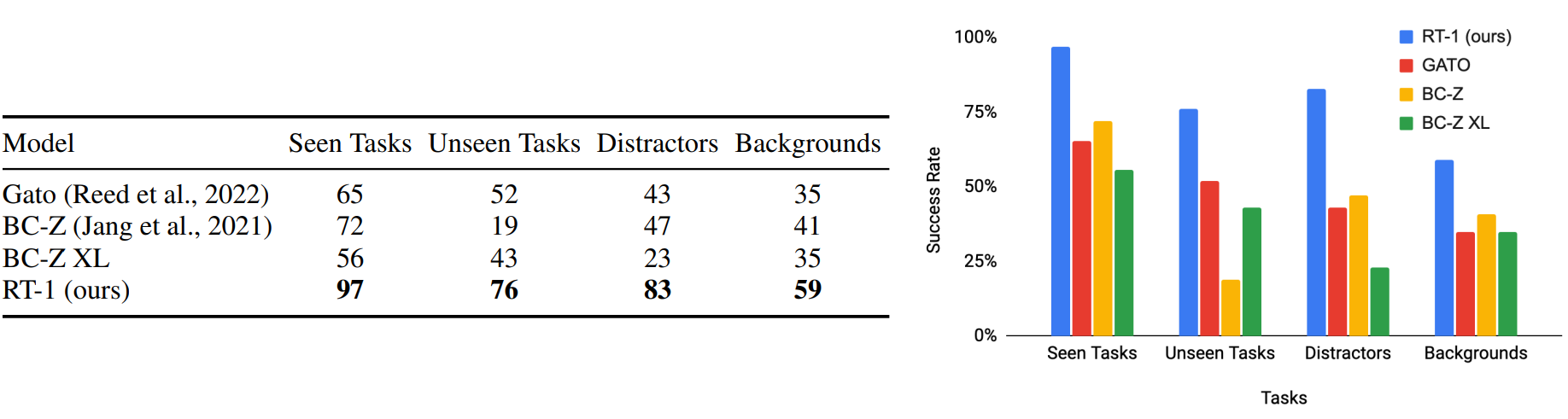
It’s very cool to see a project that works well in cluttered environments (the “backgrounds” task). I have high hopes of having a robot butler one day. A lot of robotics algorithms work in the lab, but getting it to work in my messy home is another thing altogether.
The RT1 model is able to run at 3Hz, with 100ms being allocated to each inference step. The remaining 700ms is used by other tasks in the robot. This isn’t actually that fast as far as robots go, but it is fast enough to do a lot of household tasks. It couldn’t catch a ball, but it could throw away a food wrapper.
While the paper specifies inference time, it doesn’t specify the compute used for the inference (at least not that I could find). This seems like an odd omission, though it should be possible to figure out how much is used from model size and inference time. I think the model runs on the EDR robot itself. The EDR bot is custom Google hardware, and I had some trouble finding specs for it online.
RT1 for multiple robotics platforms
Remember that issue with lack of training data we talked about above? One way to get more training data in robotics is to use recorded sessions from other robots. The problem with this is that different robots have different dynamics. Their arms are different sizes, which means that you can’t just map task execution one-to-one for the robots.
Google explores this problem by using training data from another robot (a Kuka arm). This training data was collected for a different (unrelated) paper that Google wrote. They do a three experiments here:
- train on just EDR data (EDR is the robot used for everything else in the paper)
- train on just Kuka data
- train on a combination (they use 66% EDR data and 33% Kuka data)
Just data from a different robot produces terrible results. RT1 can’t figure out how to adapt what it’s seeing to the other mechanisms. Data from just EDR does ok (22% performance on picking stuff from a bin). Data from both robots improves performance to 39% on that bin-picking task.
It’s very cool that the RT1 network is able to improve from seeing multiple robots do something. It seems obvious that using extra data from the EDR robot would have been even better, but that would also be much more expensive.
One thing I would have loved to see is more experimentation on the ratio of robot-types in training data. How much data do you need from the robot you’re actually using in order to get good performance. Some kind of trade-off curve between data from your robot and others (rather than just the two point values) would have been useful.
I’m also curious if having data from lots of robot types (instead of just two) would help. If it does, we could be entering a future where there’s one network you just download for any new robot you build. You then fine-tune on your custom robot and have high performance right away.
Long term planning
Since RT1 is intended to allow robots to perform simple actions, you need a higher level planner to accomplish larger goals. A task like “bring me a glass of water” would require actions like “go to the cabinet”, “get a glass”, “go to the sink”, etc. Google has previously worked on SayCan, which uses a large language model (like GPT) to decompose high level tasks into individual actions like this.
Google did explore using SayCan with RT1. They showed that it gets pretty good performance compared to a few other networks that have been used with SayCan. The success of long duration plans requires each individual step to go right, so it seems obvious that a model better at individual steps would succeed more at long term planning. I’m not sure the SayCan experiments that Google did show anything other than “yes, the thing we expect about long plan performance actually still works”.
Other thoughts
Since RT1 was trained only on camera images and text descriptions, it doesn’t seem to have memory. If you ask it to bring you chips, it can see if it has chips in its hand, or if you do. The current observations of the world tell it everything it needs to know about its next step in the task. I suspect that RT1 would struggle more on tasks that had “hidden state”, where recent camera images don’t contain everything it needs to know.
Since I don’t follow Google’s research very closely, I was pretty surprised by how much of RT1 was just plugging together other networks that Google had worked on. RT1 uses EfficientNet, FiLM, TokenLearner, etc. This composability is pretty cool, and makes me think that the hidden-state issue is likely to be solved by plugging RT1 together with someone else Google is already working on.
This also contrasts pretty strongly with GPT-3 (and OpenAI’s whole approach). There’s obviously a lot of truth the the “scale is all you need” aphorism, but it’s interesting to see people take a highly structured approach. I like this quite a bit, as I think it improves interpretability and predictability of the model.
I’m also curious how they deal with imitation learning’s problems. Imitation learning from pre-collected episodes often leads to a brittle distribution of actions. If the world doesn’t exactly conform to what the training episodes look like, the AI won’t be able to figure out how to recover. This is solved by things like DAgger by allowing the AI to query humans about recovery options during training. RT1 got pretty good performance, and it looks like they ignore this question entirely. I wonder why it worked so well. Maybe all the episodes started from different enough initial conditions that recovery ability was learned? Or maybe the tasks are short enough for this to not matter, and recovery is done at a higher level by things like SayCan?