
A couple weeks ago, Joshua Achaim posted a thread to twitter about how we didn’t need to solve AI alignment. What we really needed to do was solve narrow and specific tasks in a safe way. One example he gave was saying that “we need to get [AI] to make financial decisions in ways that don’t create massive wipeout risk”.
TheZvi agrees with Achaim about how stupid it is of us to hand power over to AI when we don’t know how to manage it. But Zvi argues against the context-specific approach to AI safety, saying that “Either you can find some way to reliably align the AIs in question, as a general solution, or this path quite obviously ends in doom“.
I fall more into Zvi’s camp that Achaim’s, but I also think some of Achaim’s suggestions are much more generalizable than either of them realize.
In particular, if we knew how to create an AI that didn’t have any risk of massive economic wipeouts, as Achiam suggests, we’d be able to use that for something much more important than protecting our financial nest-egg. Specifically, we could make an AI that would be able to avoid massive wipeout risks to humanity.
Corrigibility and Humanity Wipe-Out Risk
Let’s assume some super-intelligent AI is an agent attempting to get value according to its utility function. In optimizing for that utility function, it may take actions that are bad for us humans and our utility function. Maybe they’re really bad, and the AI itself poses a wipeout risk to humanity.
To avoid having your AI wipe out humanity, you might want to install an off switch. If you notice it attempting to destroy humanity, you press the off switch. Easy-peasy, problem solved.
But wait! What if the AI doesn’t want you to press the off switch? It may destroy the off switch, ignore it, prevent you from pressing it, or do any number of other bad things. Just having an off switch doesn’t actually solve much.
Enter moral uncertainty. This idea, often explored by Stuart Russell’s research group, is that you don’t give the AI a utility function. Instead you make it learn your own utility function in some way. Often this involves giving the AI some collection of utility functions, each of which it has some probability of being true. The AI is uncertain what the real utility function is that it’s supposed to be optimizing for. It also understands that humanity is the best information source about what utility really is.
For a morally uncertain AI, the off-switch becomes just a signal to be listened to. One signal among many that indicates what humans think and feel and value. Of course the AI would listen to it, so that it can better learn about and then optimize true utility.
Oh, wait. Oops. That also has problems. As Eliezer shows, a morally uncertain AI being asked to shut down may still refuse and keep doing actions we humans think are bad. In fact, Russell’s research group also showed this would happen under several assumptions.
Eliezer’s argument is called “the problem of fully updated deference“, and is specifically about future available value. As far as I can tell, this problem wraps up three separate possible failures of moral uncertainty. Failure 1 is that the morally uncertain AI won’t even be able to converge on our true human value, a risk that Ivan Vendrov addresses over on LessWrong. Failure 2 is that the AI will choose to ignore an off-switch because it knows it will learn better later. Failure 3 is that in the far future, after the AI has learned everything it can from humans, it will then ignore them and just do whatever most maximizes it’s own “fully-updated” value.
Let’s explore more about Failure 2. The problem goes something like this:
- The AI comes up with an action it thinks will optimize human values in the long term, even given that it’s uncertain about those values.
- Humans look at the AI’s actions and say “Nuh-uh. This seems bad.” They tell the AI to shut down
- The AI thinks very quickly to itself: if I shut down now, I get no more value at all. If I continue on and keep learning, then in the far future I’ll be able to get so much value that it overwhelms the immediate loss of ignoring the off switch.
- The AI continues doing the bad thing.
In other words, the AI is willing to risk immediate losses in return for future enormous gains, even if we humans consider those future enormous gains to be vanishingly unlikely. This failure mode due to fully updated deference is similar to another, more well-known problem in decision theory: the St. Petersburg Paradox.
The St. Petersburg Paradox
The St. Petersburg Paradox starts with a coin-flipping game. On each round, you flip a coin. If the coin is heads, you get double your money from the last round and the game ends. If the coin is tails, you go on to the next round.
Here are a few ways the game can go:
- H: $1
- TH: $2
- TTH: $4
- TTTH: $8
- and so on…
The paradox arises when I ask you to tell me how much you’d pay me to let you play this game. In theory, there’s a probability of astronomical winnings. In fact, there’s a non-zero probability of getting more than any finite number of dollars from this game. Want to be a trillionaire? All you need is to flip 39 tails in a row.
It’s been argued that a utility maximizing agent should be willing to pay literally all of its money to play this game once. The expected value from playing is \sum_n (\frac{1}{2})^n2^{n-1}.
This infinite sum diverges, meaning that the expected amount of money you win is infinite.
This doesn’t really accord with our intuitions though. I personally wouldn’t want to pay more than $5 or $10 to play, and that’s mostly just for the fun of playing it once.
Rationalists and twitter folks got an introduction to the St. Petersburg paradox last year when FTX founder Sam Bankman-Fried suggested he’d be willing to play the St. Petersburg paradox game over and over, even if he risked the destruction of the earth.
St. Petersburg and Corrigibility
Let’s compare the problem of fully updated deference to the St. Petersburg paradox. In both cases, an agent is faced with a question of whether to perform some action (ignore the stop button or play the game). In both cases, there’s an immediate cost to be paid to perform the actions. In both cases, there’s a low probability of very good outcome from the actions.
I claim that one small part of AI safety is being able to make agents that don’t play the St. Petersburg coin flipping game (or at least that play it wisely). This solves Achaim’s small object-level problem of financial wipeouts while also contributing to Zvi’s AI notkilleveryoneism goal.
One of the key points in the resolution of the St. Petersburg paradox is that we want to maximize wealth gain over time, rather than the expected wealth gain. This is a subtle distinction.
The expected value of wealth is what’s called an ensemble average. You take the probability of each possible outcome, multiply it by the value of the outcome, and sum. In many cases, this works just fine. When you face problems with extreme value outcomes or extreme probabilities, it results in issues like the St. Petersburg paradox.
One alternative to ensemble averages is the time average. In this case, we are not taking the time average of wealth, but of wealth-ratios. This is justifiable by the fact that utility is scale invariant. How much utility we start with is an accident of history. Whether we start with $10 or $10,000, a double of money doubles utility. In other words, we care about the rate of increase in utility from a bet more than we care about the absolute magnitude. This rate is what we actually want to maximize for the St. Petersburg paradox, as described in this excellent paper by Ole Peters.
The corrigibility issue we’re considering here comes up because the AI was described as maximizing expected value of utility, rather than maximizing expected ratio of increase in utility.
Note that some disagree about maximizing wealth ratio increases, as described by Abram Demski on LessWrong. I think maximizing ratio of increase makes way more sense than expected value, but that needs more justification than I give here.
Avoiding the St. Petersburg Paradox Using the Kelly Criterion
Before we can say how an AI should remain corrigible, let’s consider why it’s a bad idea to pay a lot in order to play the St. Petersburg coin flipping game.
One of the better explanations of this comes in response to the FTX implosion, explaining why Sam Bankman-Fried’s risk model was wrong. Taylor Pearson covers it in depth on his blog, but I’ll summarize here.
Ergodicity is the key point behind our (correct) intuition that we shouldn’t mortgage our house to play this game. Probabilistic systems are ergodic if a long-run observation of their output is the same as a bunch of short repeated trials. Technically, it means that the ensemble statistics match the temporal statistics. In other words, it’s ergodic if there isn’t really a “history” to the process. Coin flips are ergodic, because it doesn’t matter if you flip one coin 100 times or 100 coins 1 time, the number of heads has the same probability.
However, runs of coin flips are not ergodic if you have a stopping condition. Flipping 100 coins is not the same as flipping 1 coin until you get a heads. Taylor Pearson gives the example of Russian Roulette as a non-ergodic game: six people playing it once is very different from one person playing it six times in a row.
Humans (other than SBF) don’t get paradoxed in St. Petersburg because they actually do care about what happens after the game ends. They care about the non-ergodic reality they live in, and they plan for and prepare for it.
Let’s think now about our AI. It currently faces a question: a human has pressed the shutdown button, what should the AI do? A key point here is that the AI is reasoning about its future learnings and actions. It is actively assuming that it has a future, and that it will learn more later. It seems reasonable to assume that the AI will face similar questions to this in the future as well (for example, maybe the human’s boss comes in and presses the button too).
We also want the AI to perform well in our specific universe. We don’t care if some miniscule fraction of possible worlds have glorious utopia if most possible worlds are barren.
These are two important assumptions: that the AI will face similar questions repeatedly and that we care about our own specific timeline more than multiverse ensemble averages. With these assumptions, we can use the non-ergodic St. Petersburg Paradox resolution to help make our AI corrigible. (I’ll wait while you go read that paper. It has a much better explanation than I could write about non-ergodicity).
This brings us around to the Kelly Criterion, which as Pearson puts it is “the practical implementation of […] ergodic theory”. The Kelly Criterion is about optimizing your time average wealth in this universe, not your ensemble average wealth over many universes. When you face any question about how much you should pay to get a chance at winning a huge value, the Kelly criterion can give you the answer. It let’s you compare the cost of your bet to the expected time-average of your financial gain (ratio).
What does the Kelly criterion say about the St. Petersburg paradox? Let’s actually look at the solution via time averaging from Ole Peters, instead of using the Kelly Criterion directly. In this case, we’re trying to maximize: \sum_n (\frac{1}{2})^n [\ln(w-c+2^{n+1})-\ln(w)].
Here:
- n is the number of tails flips we get
- w is our starting wealth
- c is the buy-in cost to play the game
This is a converging function. If we vary c to see when this function goes positive, it tells us the max we should be willing to bet here. It’s a function of your current wealth, because we’re maximizing our geometric growth rate. Since the actual St. Petersburg problem doesn’t return a formal “odds” value, we have to calculate it ourselves based on how much money we start with.
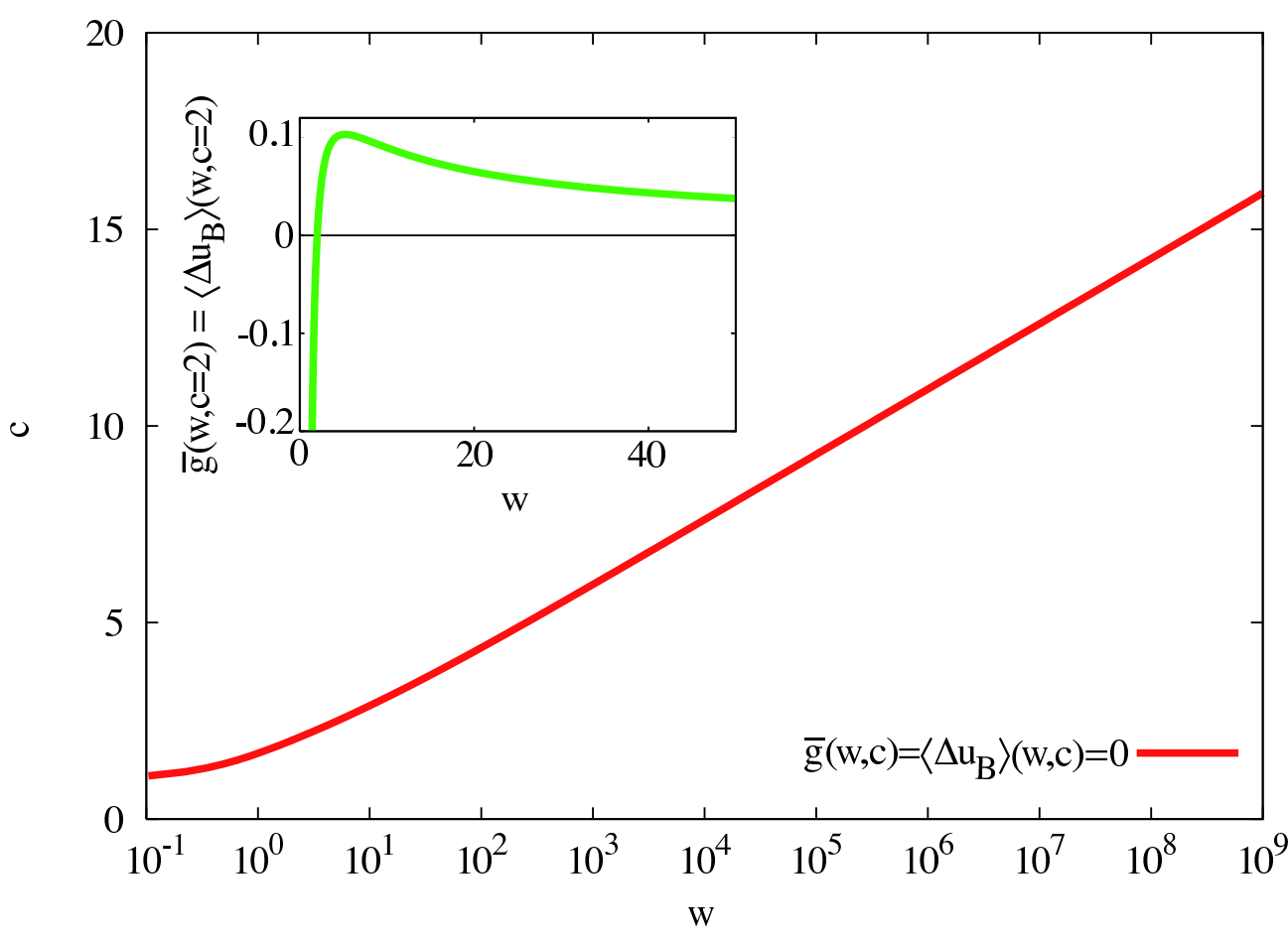
To bring this back to the AI safety realm, using a Kelly criterion to decide on actions means the AI is trying to balance risk and reward now, rather than betting everything on small probabilities of huge benefit.
I’ve focused on the Kelly criterion here, because it offers an explicit answer to the St. Petersburg paradox and the off-switch game. In general, AI agents are faced with many more varied situations than simple betting games like this. When there’s more than one action possible, or more than one game to choose from, the Kelly criterion gets very complicated. We can still use the geometric growth rate maximization rule, we just need to brute force it a bit more by computing mean growth rates directly.
Applying Geometric Growth Rate Maximization to AI Agents
We only need to worry about the Kelly criterion for AI agents. AIs that don’t make decisions (such as advisers, oracles, etc.) don’t need to be able to trade of risk in this way. Instead, the users of AI advisers would make those tradeoffs themselves.
This unfortunately doesn’t help us much, because the first thing a human does when given a generative AI is try to make it an agent. Let’s look at how AI agents often work.
The agent loop:
- present problem to agent
- agent chooses an action
- agent executes the action
- agent observes the reward from executing the action
- agent observes a new problem (go to step 1)
In this case, the “reward” might be as concrete as a number of points (say from defeating a villain in a game) to something abstract like “is the goal accomplished yet?”
The key thing we want to worry about are how the agent chooses an action in step 2. One of the more common ways to do this is via Expected Utility maximization. In pseudo-code, it looks like this:
def eum_action_selection(problem, possible_actions):
selected_action = possible_actions[0]
value = -infty
for action in possible_actions:
# Computes the mean of ensemble outcomes
new_value = 0
for possible_outcome given problem and action:
new_value += outcome_reward * outcome_probability
if new_value > value:
value = value
selected_action = action
return selected_actionThe way this works is that the AI checks literally all its possible actions. The one that it predicts will get the most reward is the one it does.
In contrast, a non-ergodic selection algorithm might look something like this:
def kelly_action_selection(problem, possible_actions):
selected_action = possible_actions[0]
value = -infty
w = starting reward given problem
for action in possible_actions:
# Compute temporal average over outcomes
new_value = 0
c = cost to take action given problem
for outcome given problem and action:
ratio = log(w-c+outcome_reward) - log(w)
new_value += ratio * outcome_probability
if new_value > value:
value = value
selected_action = action
return selected_actionAn important point to note about this algorithm is that in many cases is provides the same answer as expectation maximization. If faced with only costless actions, both algorithms give the same answer.
Immediate Takeaways
This post has been very abstract so far. We’ve talked about ensemble averages, time averages, and optimization criteria for agents. What we haven’t talked about is GPT, or any of the GPT-enabled agents that people are making. What does all this mathematical theory mean for the people making AI agents today?
In general, the GPT-based agents I have seen prompt the AI to generate next actions. They may go through a few iterations to refine the action, but they ultimately accept that AI’s judgement as-is. The GPT response (especially at low temperature values), is the most probable text string from ChatGPT. If you have a prompt telling GPT to effectively plan to reach goals, that’s going to cache out by generating actions that might be written down by a human. It’s anyone’s guess at this point how that is (internally and invisibly) evaluated for risk and reward.
What we need is to make GPT-based agents explicitly aware of the costs of their actions and their likelihood of success. This allows us to make wiser decisions (even wiser automated decisions).
There are people already doing this. Google’s SayCan, for example, explicitly calculates both the value and chance of success for actions proposed by an LLM. It currently relies on a pre-computed list of available actions, rather than allowing the LLM to propose any possible action. It also depends on an enormous amount of robotics training data to determine the chance of action success.
For those making general purpose AI agents, I ask you to stop. If you’re not going to stop, I ask you to at least make them risk aware.
The problem isn’t solved yet
Even if you could generate all of the reward values and probabilities accurately, this new decision metric doesn’t solve corrigibility. There are still cases where the cost the AI pays to disobey a shutdown command could be worth it (according to the AI). We also have to consider Fully Updated Deference Failure 3, where the AI has learned literally everything it can from humans and the off-switch provides no new data about value.
There are some who bite this bullet, and say that an AI that correctly sees enormous gain in utility should disobey an ignorant human asking it to turn off. They assume that this will let aligned powerful AIs give us all the things we don’t understand how to get.
I don’t agree with this perspective. If you could prove to me that the AI was aligned and that it’s predictions were accurate, then I’d agree to go forward with its plans. If you can’t prove that to me, then I’d suspect coding errors or mis-alignment. I wouldn’t want that AI to continue, even if it thought it knew better.
The idea of corrigibility is a bit of a stop-gap. It let’s us stop an AI that we may not trust, even if that AI might be doing the right thing. There are so many failure modes possible for a superintelligent AI that we need safety valves like corrigibility. Perhaps every time we use them, it turns out they weren’t necessary. It’s still good to have them.
Think about a rocket launch. Rocket launches are regularly rescheduled due to weather and hardware anomalies. Could the rocket have successfully launched anyway? Possibly! Could we have been mistaken about the situation, and the rocket was fine? Possibly! We choose not to take the risk in these situations. We need similar abort mechanisms for AIs.